
Towards a Theory of Bulk Orchestration
It’s a key feature of living systems, perhaps even in some ways the key feature: that even right down to a molecular scale, things are orchestrated. Molecules (or at least large ones) don’t just move around randomly, like in a liquid or a gel. Instead, what molecular biology has discovered is that there are endless active mechanisms that in effect orchestrate what even individual molecules in living systems do. But what is the result of all that orchestration? And could there perhaps be a general characterization of what happens in systems that exhibit such “bulk orchestration”? I’ve been wondering about these questions for some time. But finally now I think I may have the beginnings of some answers.
The central idea is to consider the effect that “being adapted for an overall purpose” has on the underlying operation of a system. At the outset, one might imagine that there’d be no general answer to this, and that it would always depend on the specifics of the system and the purpose. But what we’ll discover is that there is in fact typically a certain universality in what happens. Its ultimate origin is the Principle of Computational Equivalence and certain universal features of the phenomenon of computational irreducibility that it implies. But the point is that so long as a purpose is somehow “computationally simple” then—more or less regardless of what in detail the purpose is—a system that achieves it will show certain features in its behavior.
Whenever there’s computational irreducibility we can think of it as exerting a powerful force towards unpredictability and randomness (as it does, for example, in the Second Law of thermodynamics). So for a system to achieve an overall “computationally simple purpose” this computational irreducibility must in some sense be tamed, or at least contained. And in fact it’s an inevitable feature of computational irreducibility that within it there must be “pockets of computational reducibility” where simpler behavior occurs. And at some level the way computationally simple purposes must be achieved is by tapping into those pockets of reducibility.
When there’s computational irreducibility it means that there’s no simple narrative one can expect to give of how a system behaves, and no overall “mechanism” one can expect to identify for it. But one can think of pockets of computational reducibility as corresponding to at least small-scale “identifiable mechanisms”. And what we’ll discover is that when there’s a “simple overall purpose” being achieved these mechanisms tend to become more manifest. And this means that when a system is achieving an overall purpose there’s a trace of this even down in the detailed operation of the system. And that trace is what I’ve called “mechanoidal behavior”—behavior in which there are at least small-scale “mechanism-like phenomena” that we can think of as acting together through “bulk orchestration” to achieve a certain overall purpose.
The concept that there might be universal features associated with the interplay between some kind of overall simplicity and underlying computational irreducibility is something not unfamiliar. Indeed, in various forms it’s the ultimate key to our recent progress in the foundations of physics, mathematics and, in fact, biology.
In our effort to get a general understanding of bulk orchestration and the behavior of systems that “achieve purposes” there’s an analogy we can make to statistical mechanics. One might have imagined that to reach conclusions about, say, gases, we’d have to have detailed information about the motion of molecules. But in fact we know that if we just consider the whole ensemble of possible configurations of molecules, then by taking statistical averages we can deduce all sorts of properties of gases. (And, yes, the foundational reason this works we can now understand in terms of computational irreducibility, etc.)
So could we perhaps do something similar for bulk orchestration? Is there some ensemble we can identify in which wherever we look there will with overwhelming probability be certain properties? In the statistical mechanics of gases we imagine that the underlying laws of mechanics are fixed, but there’s a whole ensemble of possible initial configurations for the molecules—almost all of which turn out to have the same limiting features. But in biology, for example, we can think of different genomes as defining different rules for the development and operation of organisms. And so now what we want is a new kind of ensemble—that we can call a rulial ensemble: an ensemble of possible rules.
But in something like biology, it’s not all possible rules we want; rather, it’s rules that have been selected to “achieve the purpose” of making a successful organism. We don’t have a general way to characterize what defines biological fitness. But the key point here is that at a fundamental level we don’t need that. Instead it seems that just knowing that our fitness function is somehow computationally simple tells us enough to be able to deduce properties of our “rulial ensemble”.
But are the fitness functions of biology in fact computationally simple? I’ve recently argued that their simplicity is precisely what makes biological evolution possible. Like so many other foundational phenomena, it seems that biological evolution is a reflection of the interplay between computational simplicity—in the case of fitness functions—and underlying computational irreducibility. (In effect, organisms have a chance only because the problems they have to solve aren’t too computationally difficult.) But now we can use the simplicity of fitness functions—without knowing any more details about them—to make conclusions about the relevant rulial ensemble, and from there to begin to derive general principles associated with bulk orchestration.
When one describes why a system does what it does, there are two different approaches one can take. One can go from the bottom up and describe the underlying rules by which the system operates (in effect, its “mechanism”). Or one can go from the top down and describe what the system “achieves” (in effect, its “goal” or “purpose”). It tends to be difficult to mix these two approaches. But what we’re going to find here is that by thinking in terms of the rulial ensemble we will be able to see the general pattern of both the “upward” effect of underlying rules, and the “downward” effect of overall purposes.
What I’ll do here is just a beginning—a first exploration, both computational and conceptual, of the rulial ensemble and its consequences. But already there seem to be strong indications that by thinking in terms of the rulial ensemble one may be able to develop what amounts to a foundational theory of bulk orchestration, and with it a foundational theory of certain aspects of adaptive systems, and most notably biology.
Some First Examples
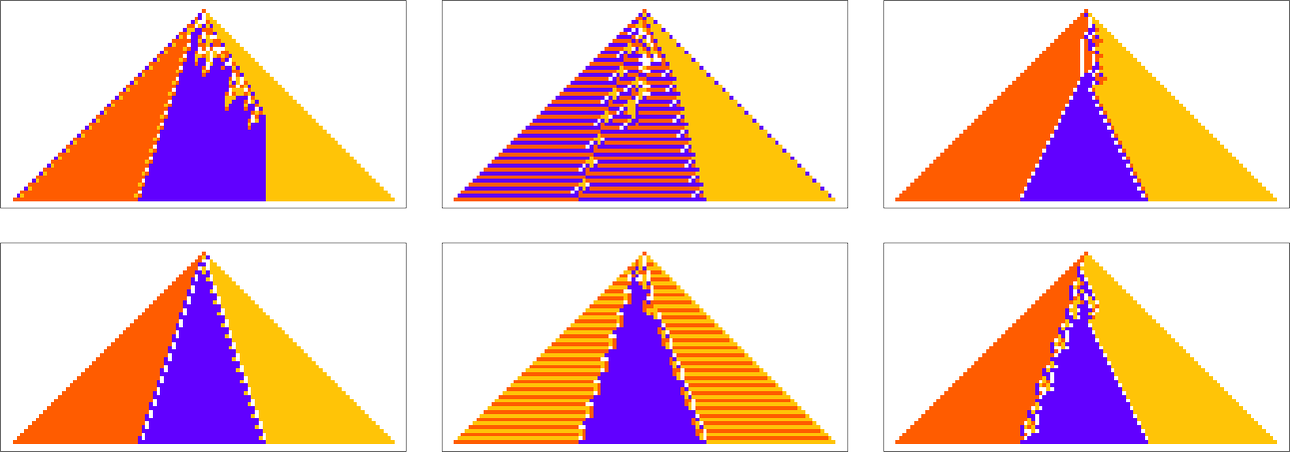
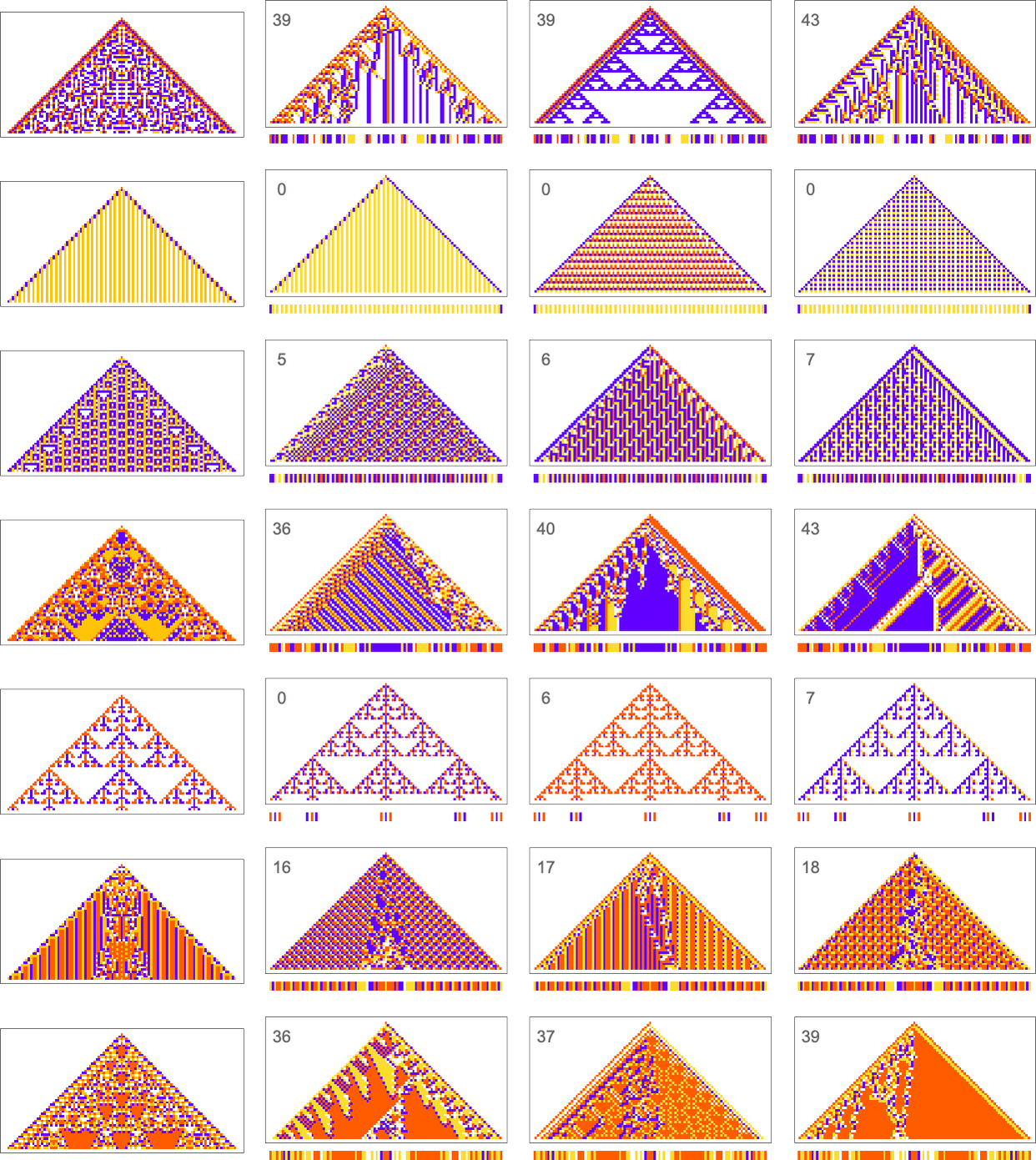
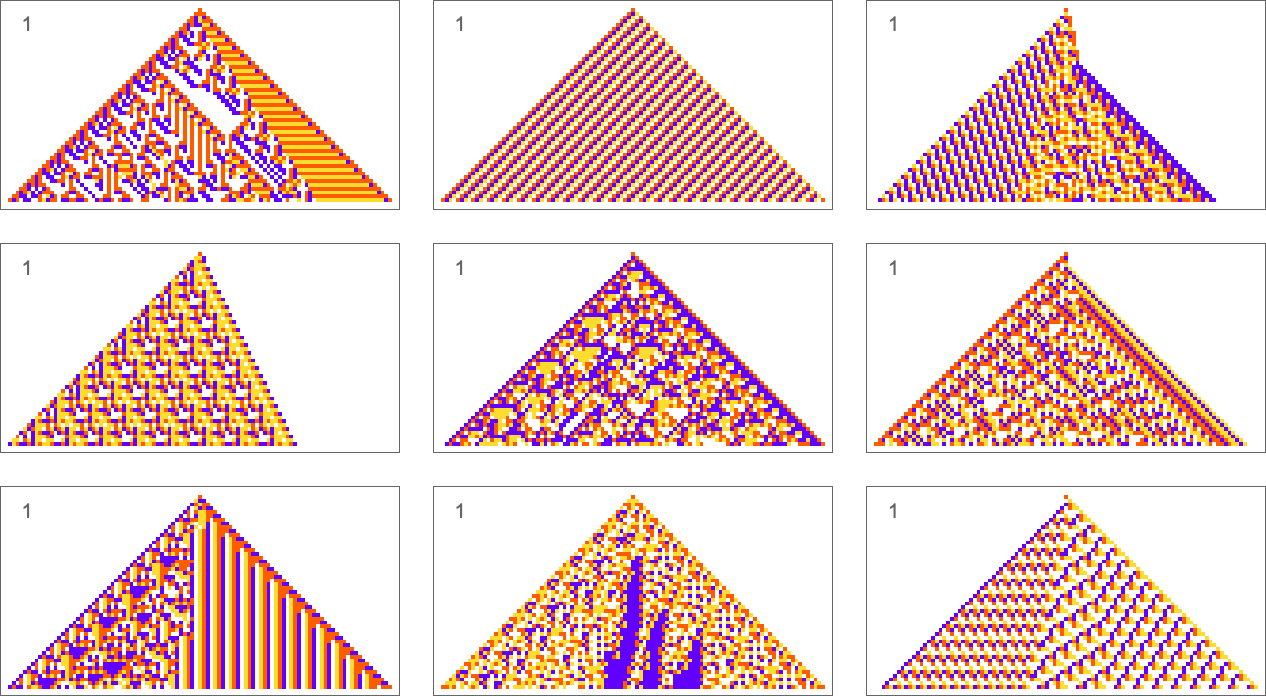
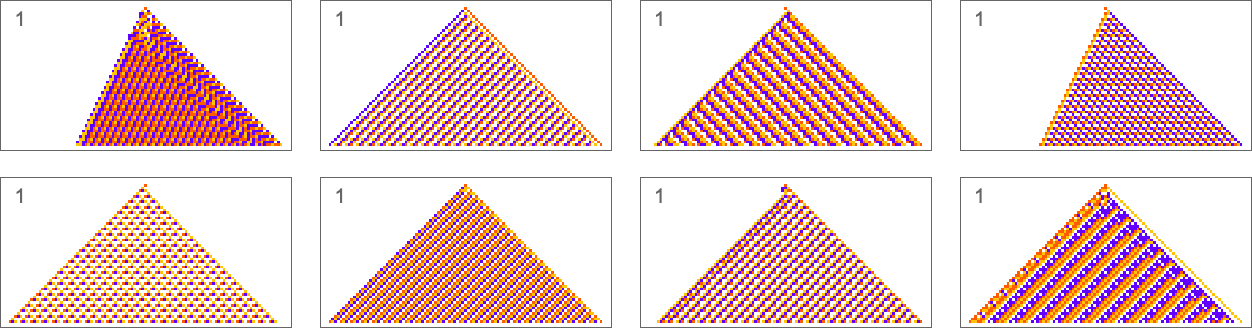
To begin our explorations and start developing our intuition let’s look at a few simple examples. We’ll use the same basic framework as in my recent work on biological evolution. The idea is to have cellular automata whose rules serve as an idealization of genotypes, and whole behavior serves as an idealization of the development of phenotypes. For our fitness function we’re going to start with something very specific: that after 50 steps (starting from a single-cell “seed”) our cellular automaton should generate “output” that consists of three equal blocks of cells colored red, blue and yellow.
Here are some examples of rules that “solve this particular problem”, in various different ways:
How can such rules be found? Well, we can use an idealization of biological evolution. Let’s consider the first rule above:
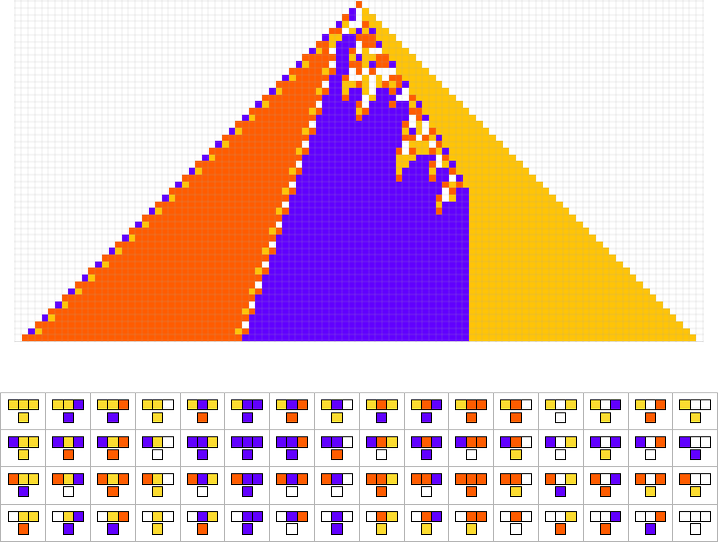
We start, say, from a null rule, then make successive random point mutations in the rule
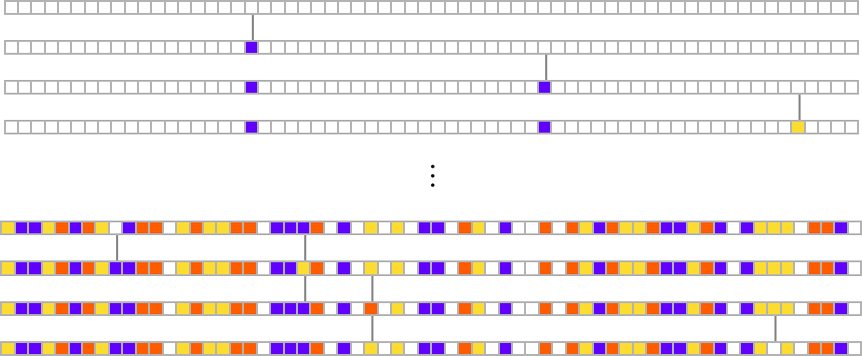
keeping those mutations that don’t take us further from achieving our goal (and dropping those that do, each indicated here by a red dot):
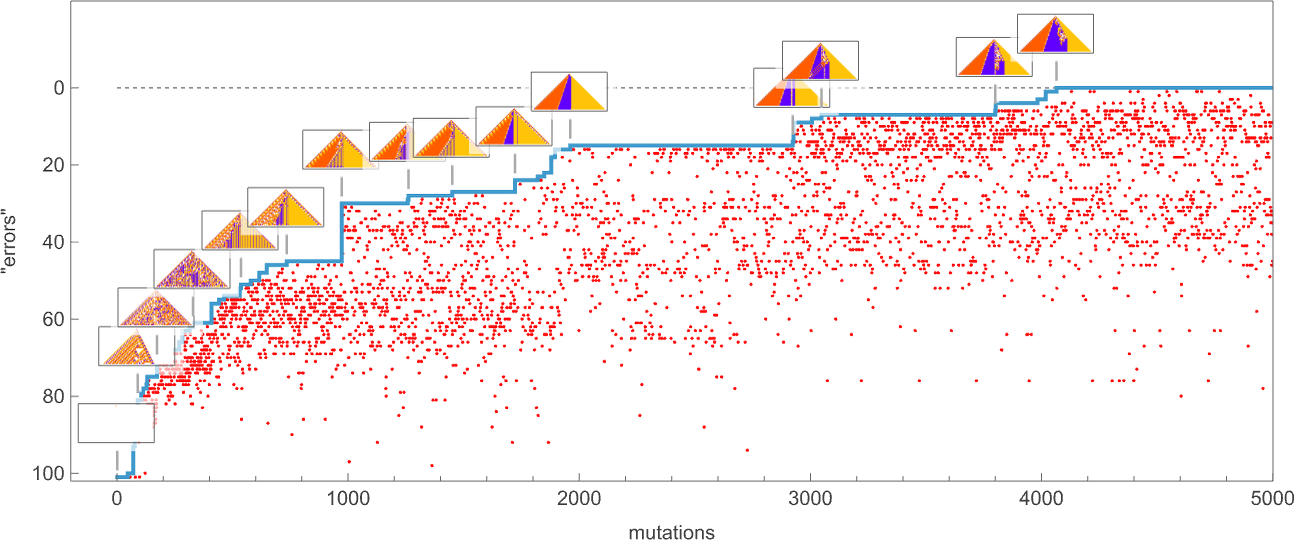
The result is that we “progressively adapt” over the course of a few thousand mutations to successively reduce the number of “errors” and eventually (and in this case, perfectly) achieve our goal:
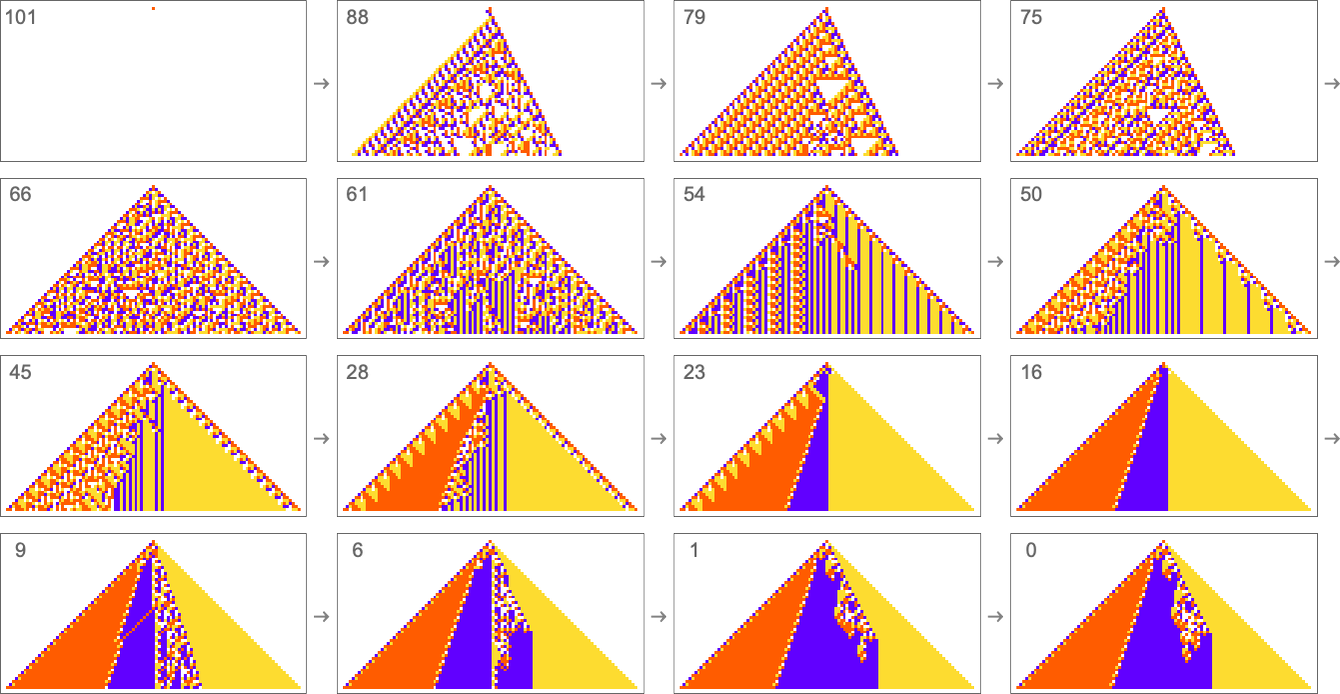
Early in this sequence there’s lots of computational irreducibility in evidence. But in the process of adapting to achieve our goal the computational irreducibility progressively gets “contained” and in effect squeezed out, until eventually the final solution in this case has an almost completely simple structure.
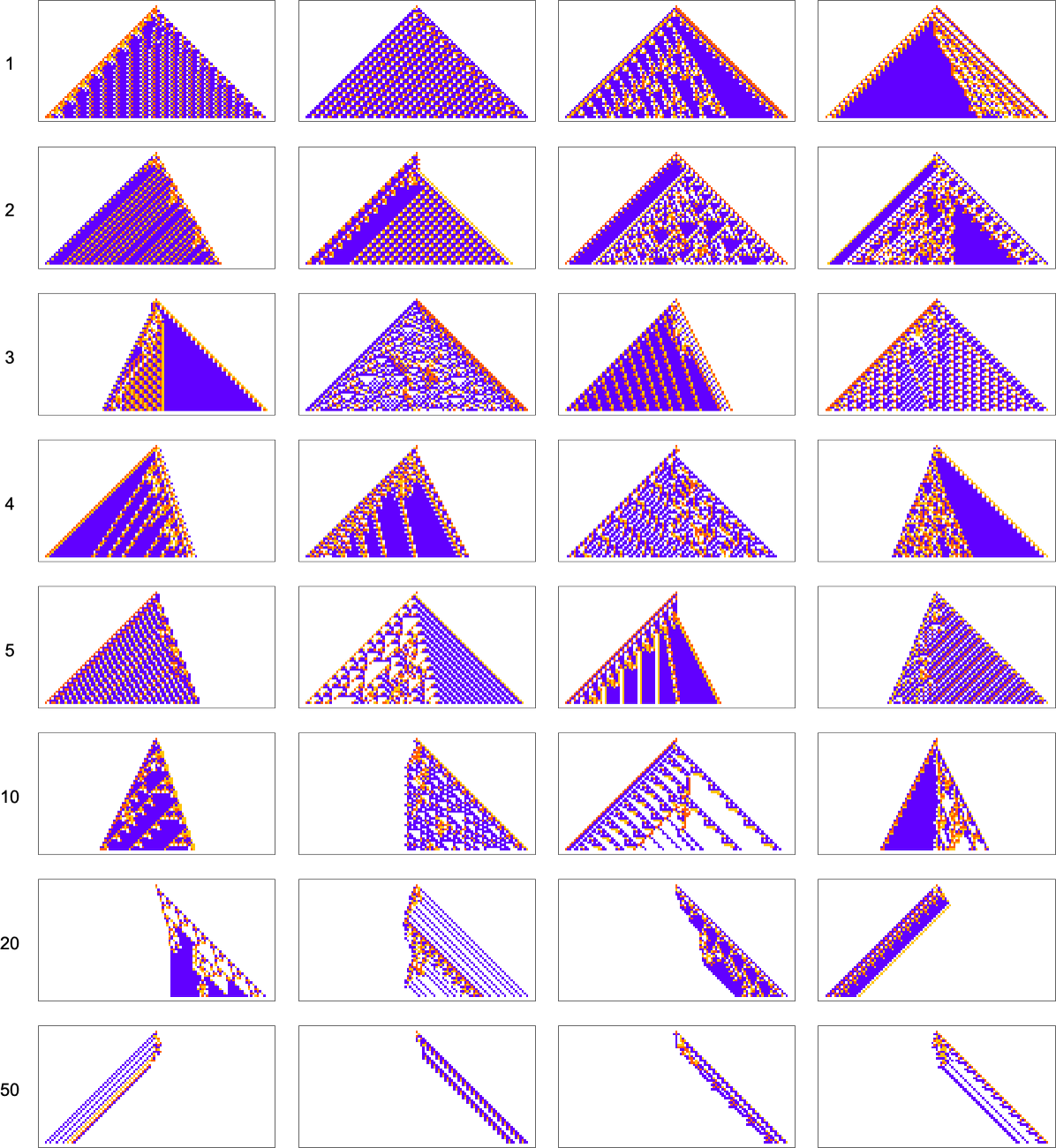
The example we’ve just seen succeeds in exactly achieving the objective we defined—though it takes about 4000 steps of adaptive evolution to do so. But if we limit the number of steps of adaptive evolution then in general we won’t be able to reach the exact objective we’ve defined. But here are some results we get with 10,000 steps of adaptive evolution (sorted by how close they get):
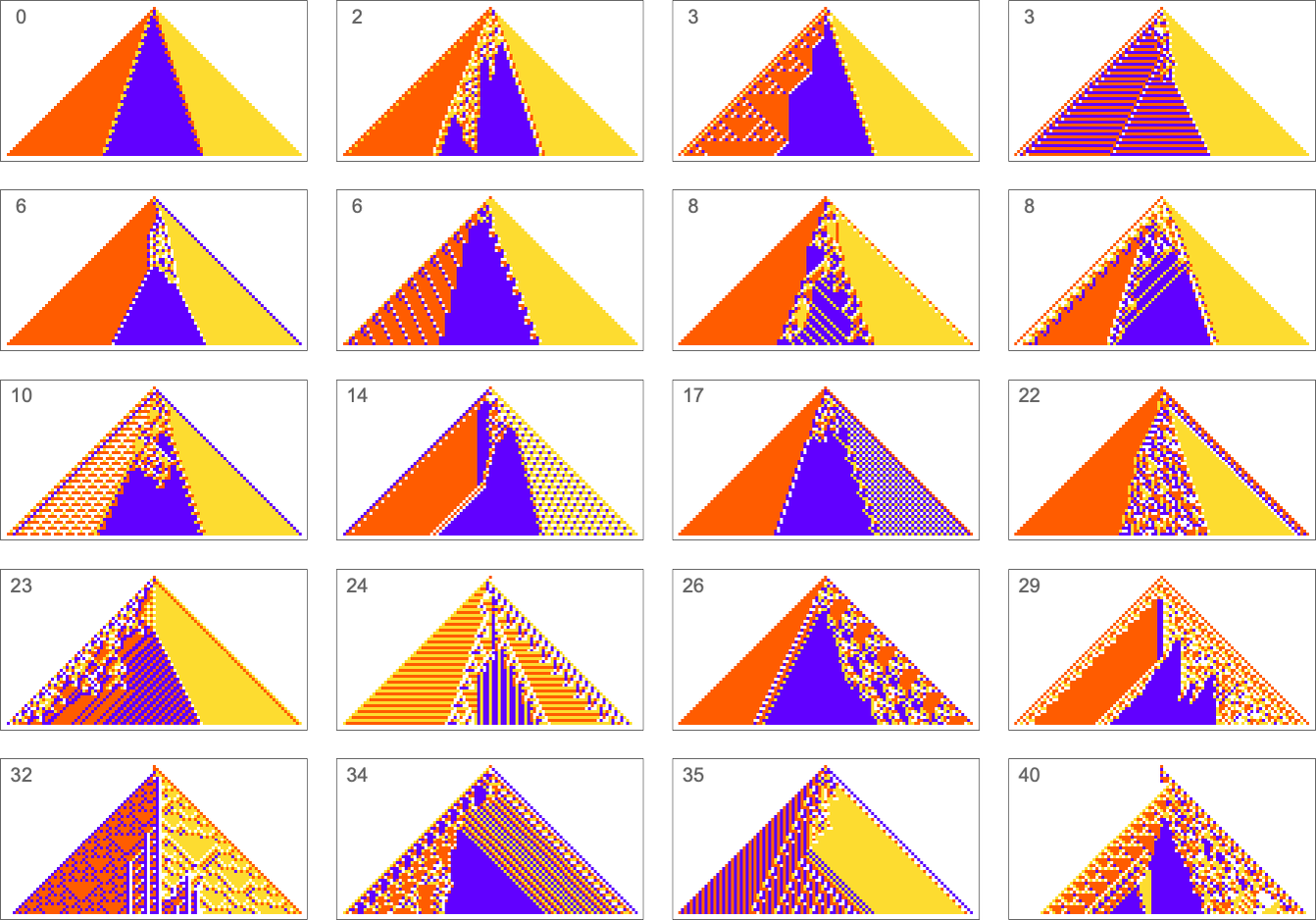
In all cases there’s a certain amount of “identifiable mechanism” to what these rules do. Yes, there can be patches of complex—and presumably computationally irreducible—behavior. But particularly the rules that do better at achieving our exact objective tend to “keep this computational irreducibility at bay”, and emphasize their “simple mechanisms”.
So what we see is that among all possible rules, those that get even close to achieving the “purpose” we have set in effect show at least “patches of mechanism”. In other words, the imposition of a purpose selects out rules that “exhibit mechanism”, and show what we’ve called mechanoidal behavior.
The Concept of Mutational Complexity
In the last section we saw that adaptive evolution can find (4-color) cellular automaton rules that generate the particular ![]() output we specified. But what about other kinds of output?
output we specified. But what about other kinds of output?
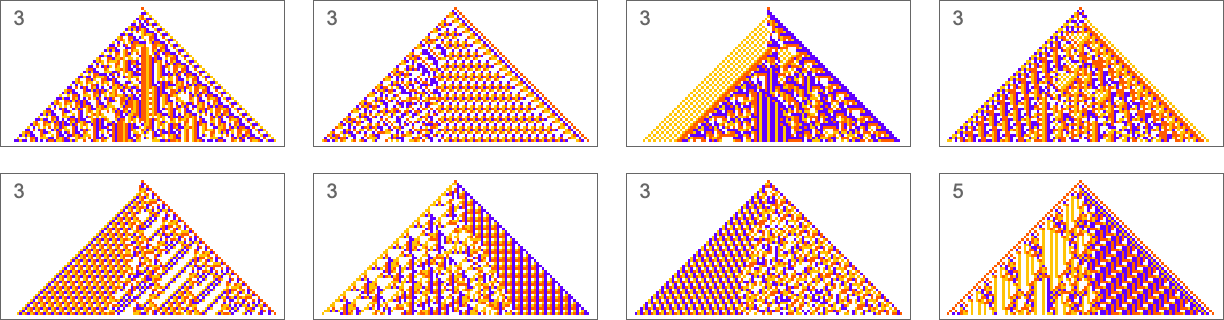
What we manage to get will depend on how much “effort” of adaptive evolution we put in. If we limit ourselves to 10,000 steps of adaptive evolution here are some examples of what happens:
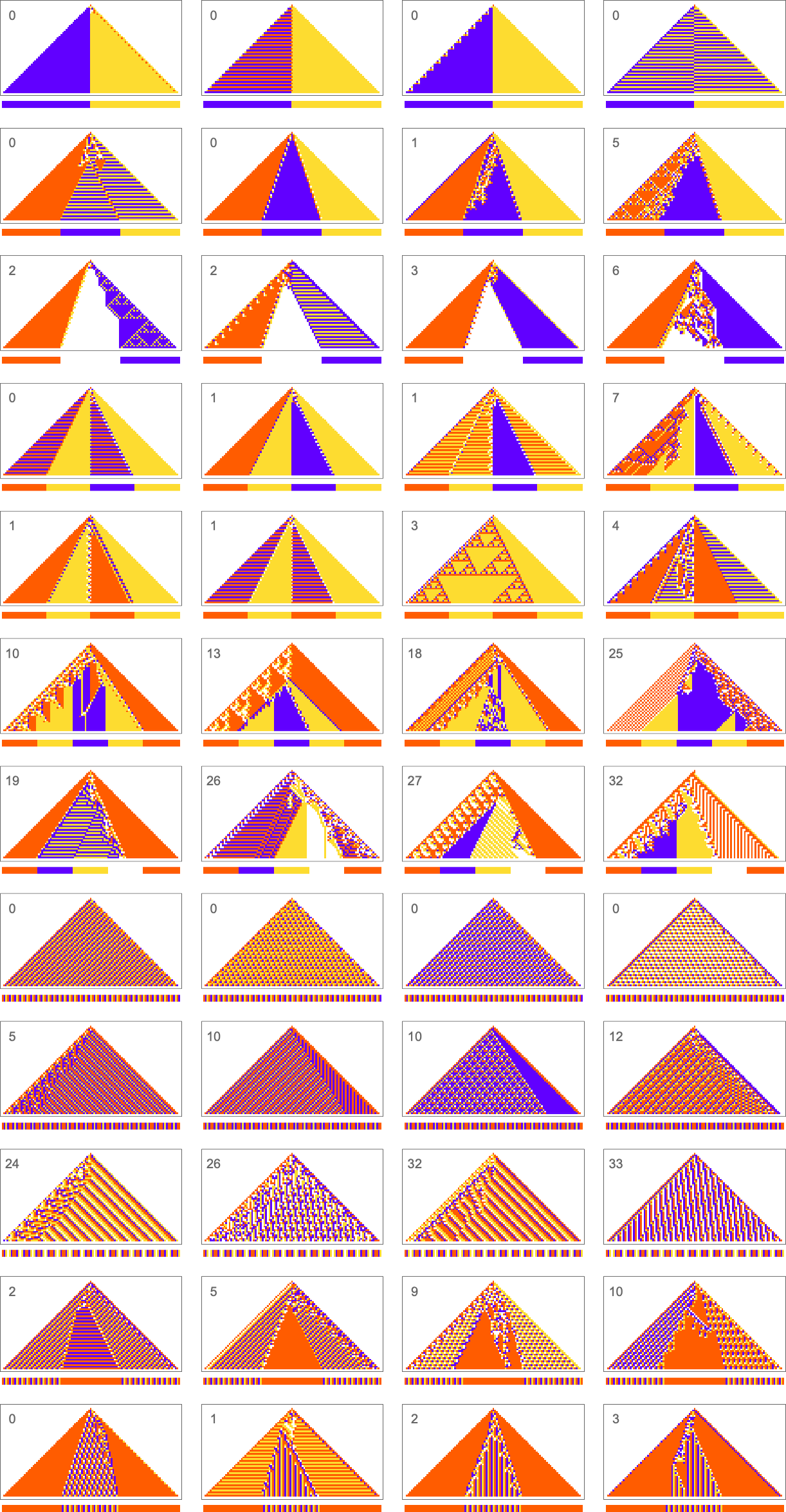
At a qualitative level the main takeaway here is that it seems that the “simpler” the objective is, the more closely it’s likely to be achieved by a given number of steps of adaptive evolution.
Looking at the first (i.e. “ultimately most successful”) examples above, here’s how they’re reached in the course of adaptive evolution:
And we see that the “simpler” sequences are reached both more successfully and more quickly; in effect they seem to be “easier” for adaptive evolution to generate.
But what do we mean by “simpler” here? In qualitative terms we can think of the “simplicity” of a sequence as being characterized by how short a description we can find of it. We might try to compress the sequence, say using some standard practical compression technique, like run-length encoding, block encoding or dictionary encoding. And for the sequences we’re using above, these will (mostly) agree about what’s simpler and what’s not. And then what we find is that sequences that are “simpler” in this kind of characterization tend to be ones that are easier for adaptive evolution to produce.
But, actually, our study of adaptive evolution itself gives us a way to characterize the simplicity—or complexity—of a sequence: we can consider a sequence more complex if the typical number of mutations it takes to come up with a rule to generate the sequence is larger. And we can define this number of mutations to be what we can call the “mutational complexity” of a sequence.
There are lots of details in tightening up this definition. But in some sense what we’re saying is that we can characterize the complexity of a sequence by how hard it is for adaptive evolution to get it generated.
To get more quantitative we have to address the issue that if we run adaptive evolution multiple times, it’ll generally take different numbers of steps to be able to get a particular sequence generated, or, say, to get to the point where there are fewer than m “errors” in the generated sequence. And, sometimes, by the way, a particular run of adaptive evolution might “get stuck” and never be able to generate a particular sequence—at least (as we’ll discuss below) with the kind of rules and single point mutations we’re using here.
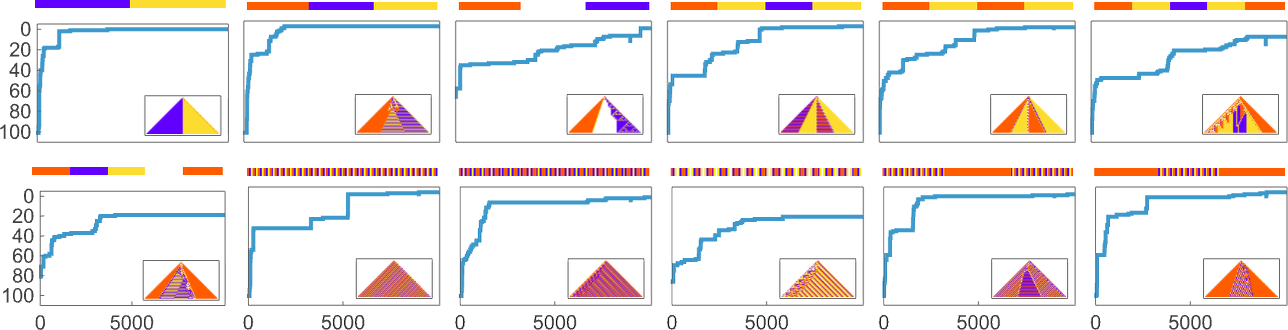
But we can still compute the probability—across many runs of adaptive evolution—to have reached a specified sequence within m errors after a certain number of steps. And this shows how that probability builds up for the sequences we saw above:

And we immediately see more quantitatively that some sequences are faster and easier to reach than others.
We can go even further by computing in each case the median number of adaptive steps needed to get “within m errors” of each sequence:

Picking a certain “desired fidelity” (say allowing a maximum of 20 errors) we then get at least one estimate of mutational complexity for our sequences:
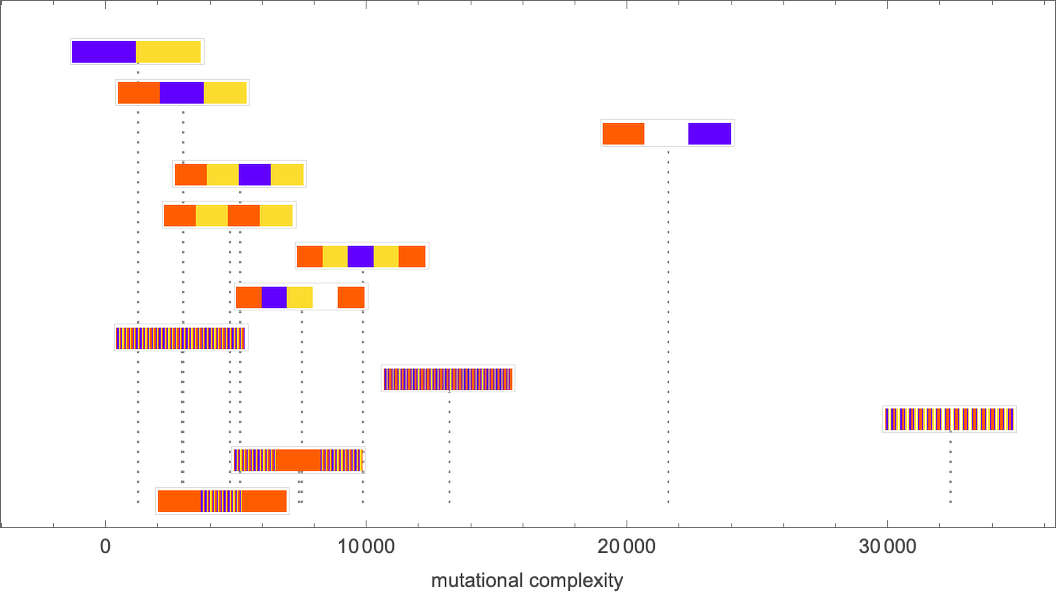
Needless to say, these kinds of numerical measures are at best a very coarse way to characterize the difficulty of being able to generate a given sequence through rules produced by adaptive evolution. And, for example, instead of just looking at the probability to reach a given “fidelity” we could be looking at all sorts of distributions and correlations. But in developing our intuition about the rulial ensemble it’s useful to see how we can derive even an admittedly coarse specific numerical measure of the “difficulty of reaching a sequence” through adaptive evolution.
Possible and Impossible Objectives
We’ve seen above that some sequences are easier to reach by adaptive evolution than others. But can any sequence we might look for actually be found at all? In other words—regardless of whether adaptive evolution can find it—is there in fact any cellular automaton rule at all (say a 4-color one) that successfully generates any given sequence?
It’s easy to see that in the end there must be sequences that can’t be generated in this way. There are 443 possible 4-color cellular automaton rules. But even though that’s a large number, the number of possible 4-color length-101 sequences is still much larger: 4101 ≈ 1061. So that means it’s inevitable that some of these sequences will not appear as the output from any 4-color cellular automaton rule (run from a single-cell initial condition for 50 steps). (We can think of such sequences as having too high an “algorithmic complexity” to be generated from a “program” as short as a 4-color cellular automaton rule.)
But what about sequences that are “simple” with respect to our qualitative criteria above? Whenever we succeeded above in finding them by adaptive evolution then we obviously know they can be generated. But in general this is a quintessential computationally irreducible question—so that in effect the only way to know for sure whether there’s any rule that can generate a particular sequence is just to explicitly search through all ≈ 1038 possible rules.
We can get some intuition, however, by looking at much simpler cases. Consider, for example, the 128 (quiescent) “elementary” cellular automata (with k = 2, r =1):

The number of distinct sequences they can generate after t steps quickly stabilizes (the maximum is 32)
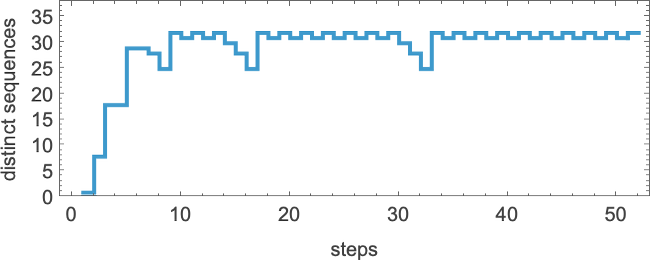
but this is soon much smaller than the total number of possible sequences of the same length (
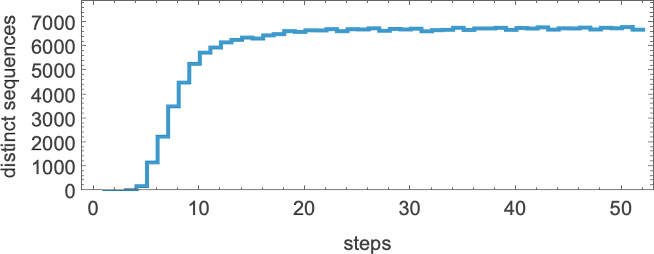
So what are the sequences that get “left out” by cellular automata? Already by step 2 a quiescent elementary cellular automaton can only produce 14 of the 32 possible sequences—with sequences such as ![]() and
and ![]() being among those excluded. One might think that one would be able to characterize excluded sequences by saying that certain fixed blocks of cells could not occur at any step in any rule. And indeed that happens for the r = 1/2 rules. But for the quiescent elementary cellular automata—with r = 1—it seems as if every block of any given size will eventually occur, presumably courtesy of the likes of rule 30.
being among those excluded. One might think that one would be able to characterize excluded sequences by saying that certain fixed blocks of cells could not occur at any step in any rule. And indeed that happens for the r = 1/2 rules. But for the quiescent elementary cellular automata—with r = 1—it seems as if every block of any given size will eventually occur, presumably courtesy of the likes of rule 30.
What about, say, periodic sequences? Here are some examples that no quiescent elementary cellular automaton can generate:

And, yes, these are, by most standards, quite “simple” sequences. But they just happen not to be “simple” for elementary cellular automata. And indeed we can expect that there will be plenty of such “coincidentally unreachable” but “seemingly simple” sequences even for our 4-color rules. But we can also expect that even if we can’t precisely reach some objective sequence, we’ll still be able to get to a sequence that is close. (The minimum “error” is, for example, 4 cells out of 15 for the first sequence above, and 2 for the last sequence).
But there still remains the question of whether adaptive evolution will be able to find such sequences. For the very simple case of quiescent elementary cellular automata we can readily map out the complete multiway graph of all possible mutations between rules. Here’s what we get if we run all possible rules for 3 steps, then show possible outcomes as nodes, and possible mutations between rules as edges (the edges are undirected, because every mutation can go either way):
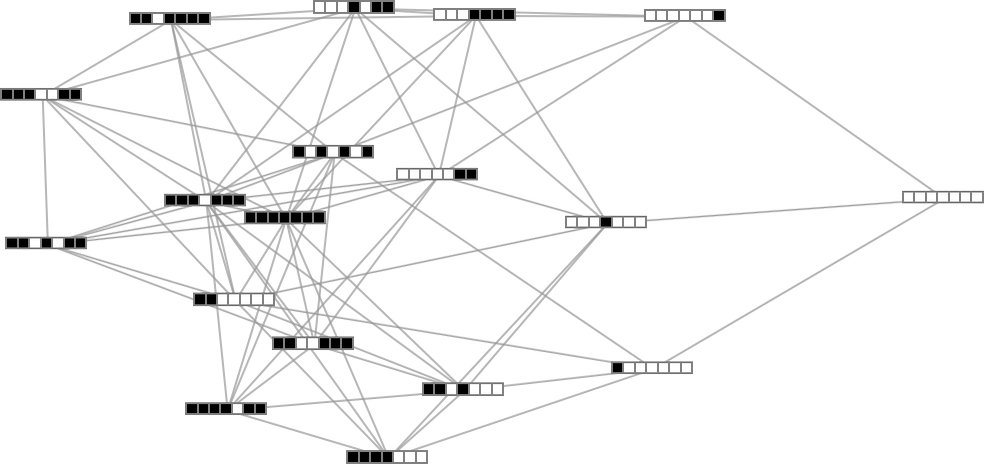
That this graph has only 18 nodes reflects the fact that quiescent elementary cellular automata can produce only 18 of the 128 possible length-7 sequences. But even within these 18 sequences there are ones that cannot be reached through the adaptive evolution process we are using.
For example, let’s say our goal is to generate the sequence ![]() (or, rather, to find a rule that will do so). If we start from the null rule—which generates
(or, rather, to find a rule that will do so). If we start from the null rule—which generates ![]() —then our adaptive evolution process defines a foliated version of the multiway graph above:
—then our adaptive evolution process defines a foliated version of the multiway graph above:
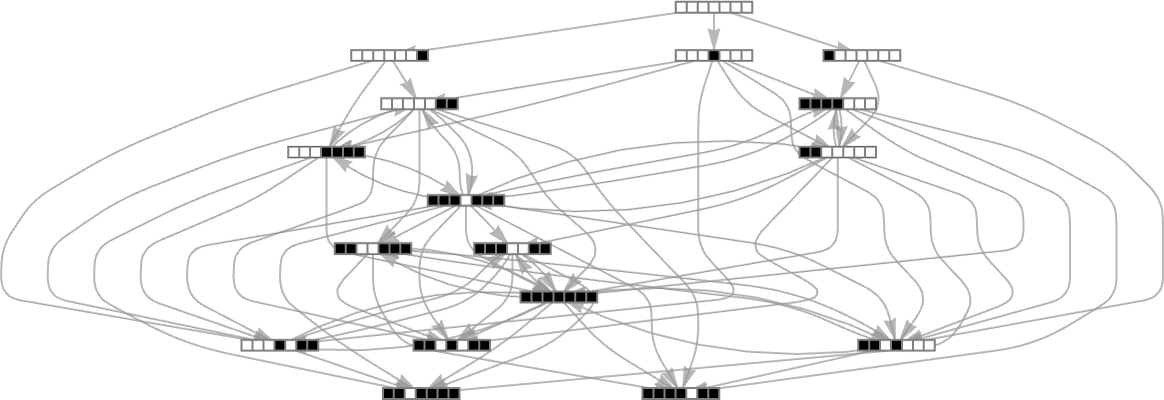
Starting from ![]() some paths (i.e. sequences of mutations) successfully reach
some paths (i.e. sequences of mutations) successfully reach ![]() . But this only happens about 25% of the time. The rest of the time the adaptive process gets stuck at
. But this only happens about 25% of the time. The rest of the time the adaptive process gets stuck at ![]() or
or ![]() and never reaches
and never reaches ![]() :
:
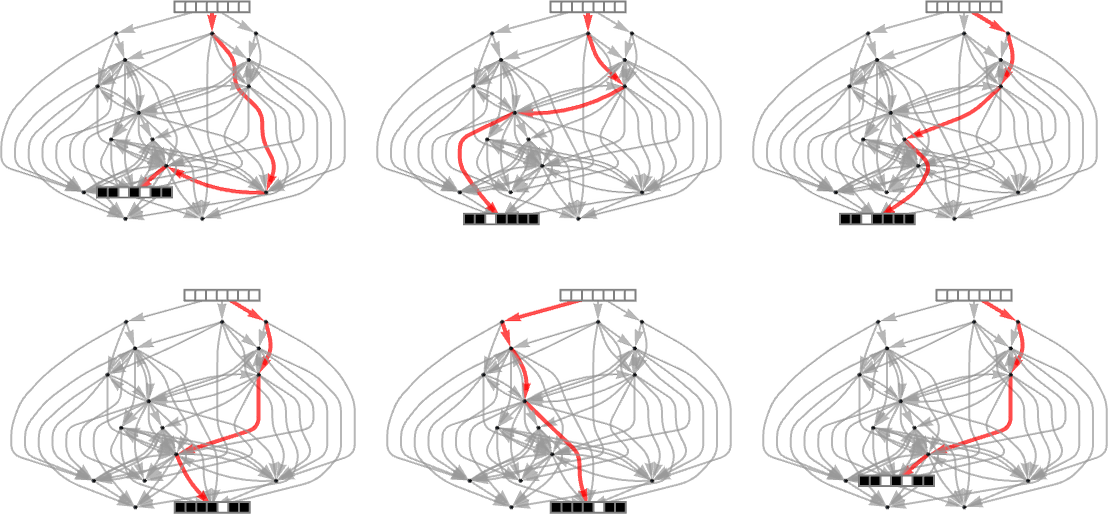
So what happens if we look at larger cellular automaton rule spaces? In such cases we can’t expect to trace the full multiway graph of possible mutations. And if we pick a sequence at random as our target, then for a long sequence the overwhelming probability is that it won’t be reachable at all by any cellular automaton with a rule of a given type. But if we start from a rule—say picked at random—and use its output as our target, then this guarantees that there’s at least one rule that produces this sequence. And then we can ask how difficult it is for adaptive evolution to find a rule that works (most likely not the original one).
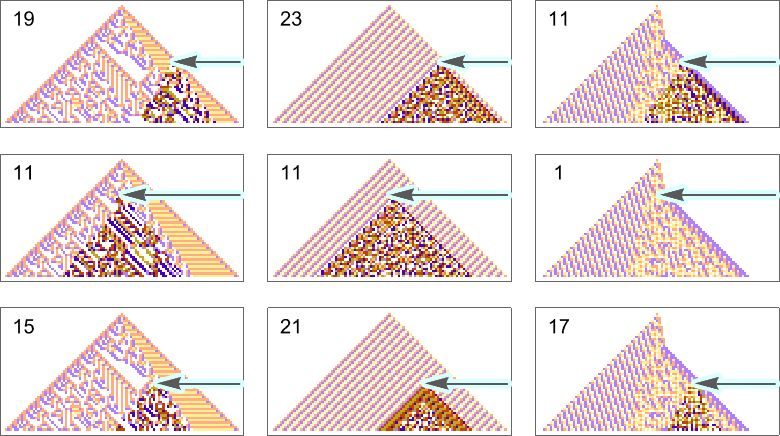
Here are some examples—with the original rule on the left, and the best results found from 10,000 steps of adaptive evolution on the right:
What we see is fairly clear: when the pattern generated by the original rule looks simple, adaptive evolution can readily find rules that successfully produce the same output, albeit sometimes in quite different ways. But when the pattern generated by the original rule is more complicated, adaptive evolution typically won’t be able to find a rule that exactly reproduces its output. And so, for examples, in the cases shown here many errors remain even in the “best results” after 10,000 steps of adaptive evolution.
Ultimately this not surprising. When we pick a cellular automaton rule at random, it’ll often show computational irreducibility. And in a sense all we’re seeing here is that adaptive evolution can’t “break” computational irreducibility. Or, put another way, computationally irreducible processes generate mutational complexity.
Other Objective Functions
In everything we’ve done so far we’ve been considering a particular type of “goal”: to have a cellular automaton produce a specified arrangement of cells after a certain number of steps. But what about other types of goals? We’ll look at several here. The general features of what will happen with them follow what we’ve already seen, but each will show some new effects and will provide some new perspectives.
Vertical Sequences
As a first example, let’s consider trying to match not the horizontal arrangement of cells, but the vertical one—in particular the sequence of colors in the center column of the cellular automaton pattern. Here’s what we get with the goal of having a block of red cells followed by an equal block of blue:
The results are quite diverse and “creative”. But it’s notable that in all cases there’s definite “mechanism” to be seen “right around the center column”. There’s all sorts of complexity away from the center column, but it’s sufficiently “contained” that the center column itself can achieve its “simple goal”.
Things are similar if we ask to get three blocks of color rather than two—though this goal turns out to be somewhat more difficult to achieve:
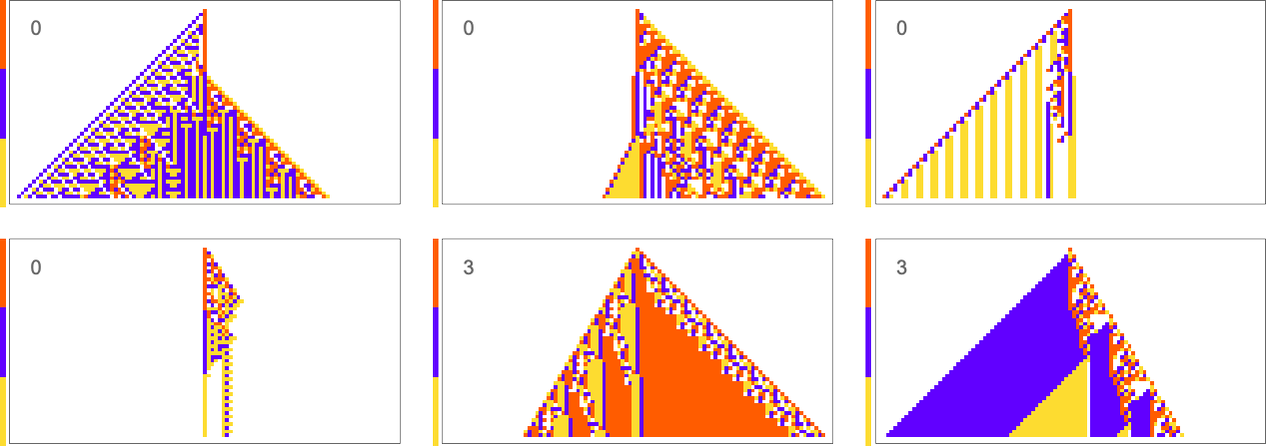
It’s also possible to get ![]() :
:

And in general the difficulty of getting a particular vertical sequence of blocks tends to track the difficulty of getting the corresponding horizontal sequence of blocks. Or, in other words, the pattern of mutational complexity seems to be similar for sequences associated with horizontal and vertical goals.
This also seems to be true for periodic sequences. Alternating colors are easy to achieve, with many “tricks” being possible in this case:
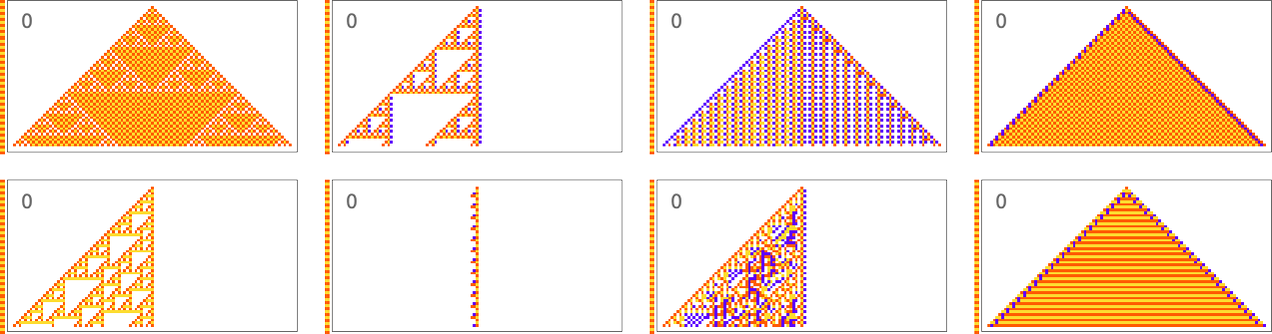
A sequence with period 5 is pretty much the same story:

When the period gets more comparable to the number of cellular automaton steps that we’re sampling it for, the “solutions” get wilder:
And some of them are quite “fragile”, and don’t “generalize” beyond the original number of steps for which they were adapted:
Color Frequencies in Output
The types of goals we’ve considered so far have all involved trying to get exact matches to specified sequences. But what if we just ask for an average result? For example, what if we ask for all 4 colors to occur with equal frequency in our output, but allow them to be arranged in any way? With the same adaptive evolution setup as before we rather quickly find “solutions” (where because we’re running for 50 steps and getting patterns of width 101, we’re always “off by at least 1” relative to the exact 25:25:25:25 result):
A few of these solutions seem to have “figured out a mechanism” to get all colors equally. But others seem like they just “happen to work”. And indeed, taking the first three cases here, this shows the relative numbers of cells of different colors obtained at successive steps in running the cellular automaton:
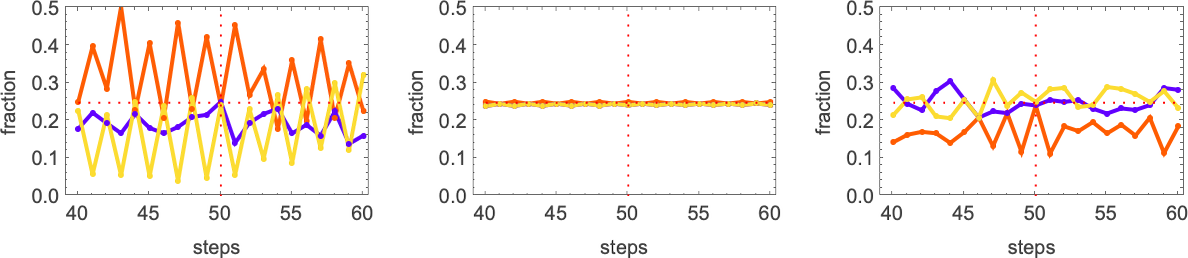
The pattern that looks simple consistently has equal numbers of each color at every step. The others just “happen to hit equality” after running for exactly 50 steps, but on either side don’t achieve equality.
And, actually, it turns out that all these solutions are in some sense quite fragile. Change the color of just one cell and one typically gets an expanding region of change—that takes the output far from color equality:
So how can we get rules that more robustly achieve our color equality objective? One approach is to force the adaptive evolution to “take account of possible perturbations” by applying a few perturbations at every adaptive evolution step, and keeping a particular mutation only if neither it, nor any of its perturbed versions, has lower fitness than before.
Here’s an example of one particular sequence of successive rules obtained in this way:
And now if we apply perturbations to the final result, it doesn’t change much:

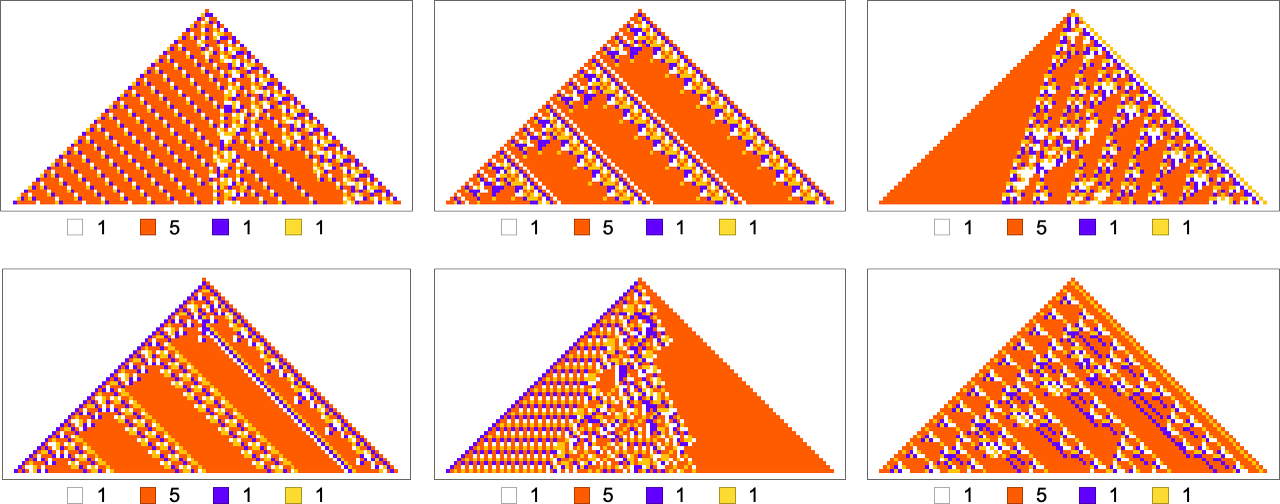
It’s notable that this robust solution looks simple. And indeed that’s common, with a few other examples of robust, exact solutions being:
In effect it seems that requiring a robust, exact solution “forces out” computational irreducibility, leaving only readily reducible patterns. If we relax the constraint of being an exact solution even a little, though, more complex behavior quickly creeps in:
Whole-Pattern Color Frequencies
We’ve just looked at trying to achieve particular frequencies of colors in the “output” of a cellular automaton (after running for 50 steps). But what if we try to achieve certain frequencies of colors throughout the pattern produced by the cellular automaton?
For example, let’s say that our goal is to have color frequencies in the ratios: ![]() . Adaptive evolution fairly easily finds good “solutions” for this:
. Adaptive evolution fairly easily finds good “solutions” for this:
And in fact it does so for any “relative red level”:
But if we plot the median number of adaptive evolution steps needed to achieve these results (i.e. our approximation to mutational complexity) we see that there’s a systematic increase with “red level”:
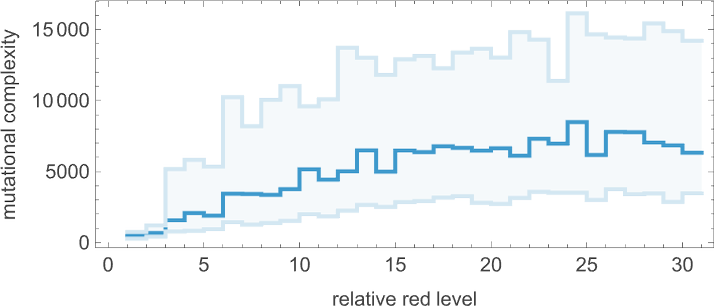
In effect, the higher the red level the “more stringent” the constraints we’re trying to satisfy are—and the more steps of adaptive evolution it takes to do that. But looking at the actual patterns obtained at different red levels, we also see something else: that as the constraints get more stringent, the pattern seems to have computational irreducibility progressively “squeezed out” of them—leaving behavior that seems more and more mechanoidal.
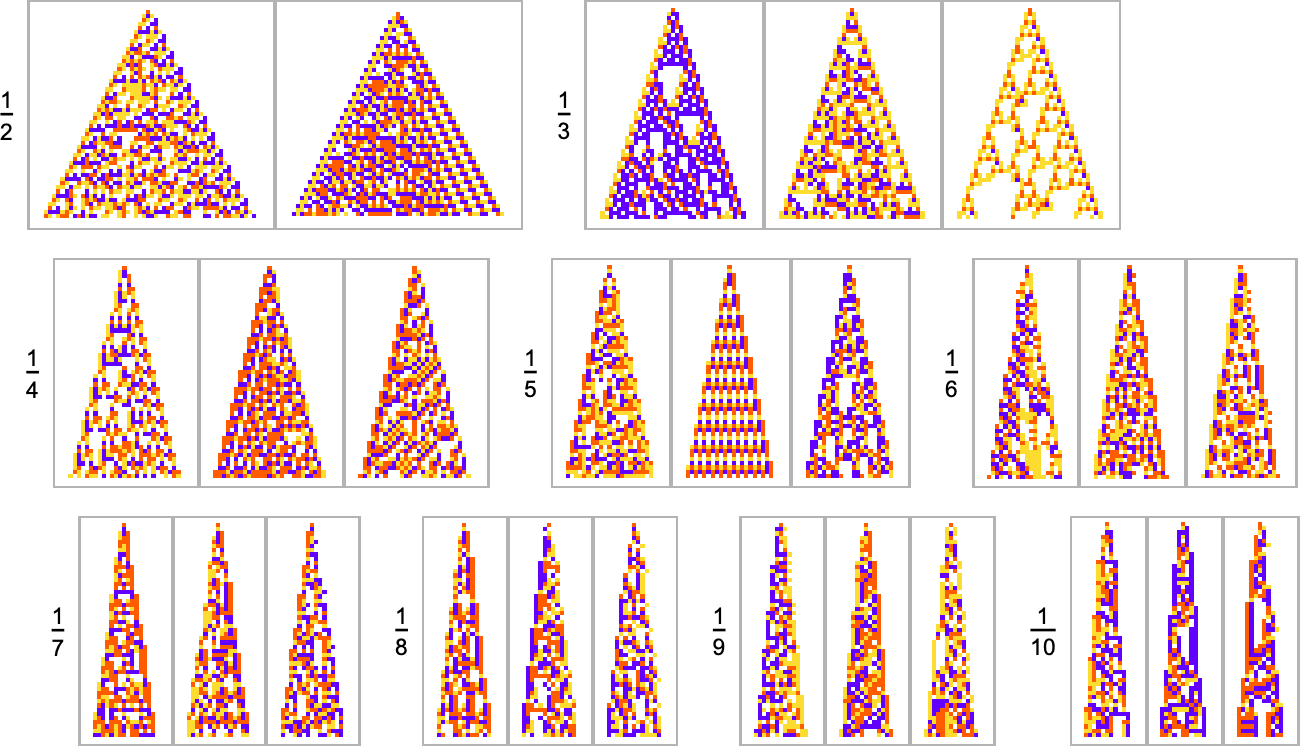
As another example along the same lines, consider goals of the form ![]() . Here are results one gets varying the “white level”:
. Here are results one gets varying the “white level”:
We see two rather different approaches being taken to the “problem of having more white”. When the white level isn’t too large, the pattern just gets “airier”, with more white inside. But eventually the pattern tends to contract, “leaving room” for white outside.
Growth Shapes
In most of what we’ve done so far, the overall “shapes” of our cellular automaton patterns have ended up always just being simple triangles that expand by one cell on each side at each step—though we just saw that with sufficiently stringent constraints on colors they’re forced to be different shapes. But what if our actual goal is to achieve a certain shape? For example, let’s say we try to get triangular patterns that grow at a particular rate on each side.
Here are some results for growth rates of the form 1/n (i.e. growing by an average of 1 cell every n steps):
This is the sequence of adaptive evolution steps that led to the first example of growth rate ![]()
and this is the corresponding sequence for growth rate ![]() :
:

And although the interiors of most of the final patterns here are complicated, their outer boundaries tend to be simple—at least for small n—and in a sense “very mechanically” generate the exact target growth rate:
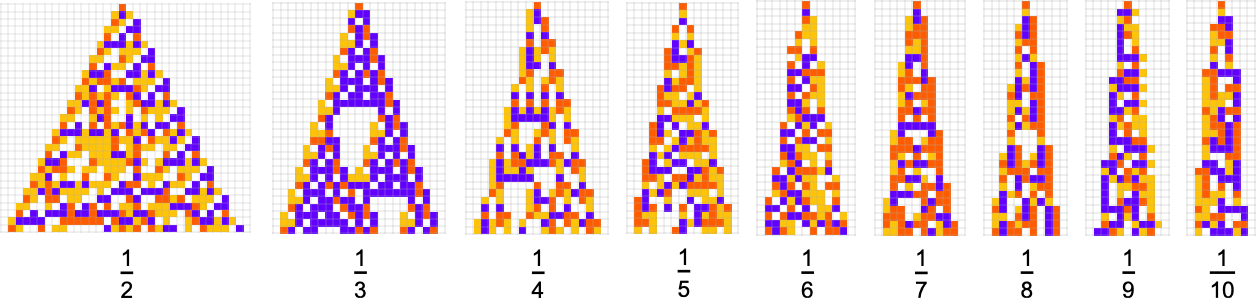
For larger n, things get more complicated—and adaptive evolution doesn’t typically “find an exact solution”. And if we run our “solutions” longer we see that—particularly for larger n—they often don’t “generalize” very well, and soon start deviating from their target growth rates:
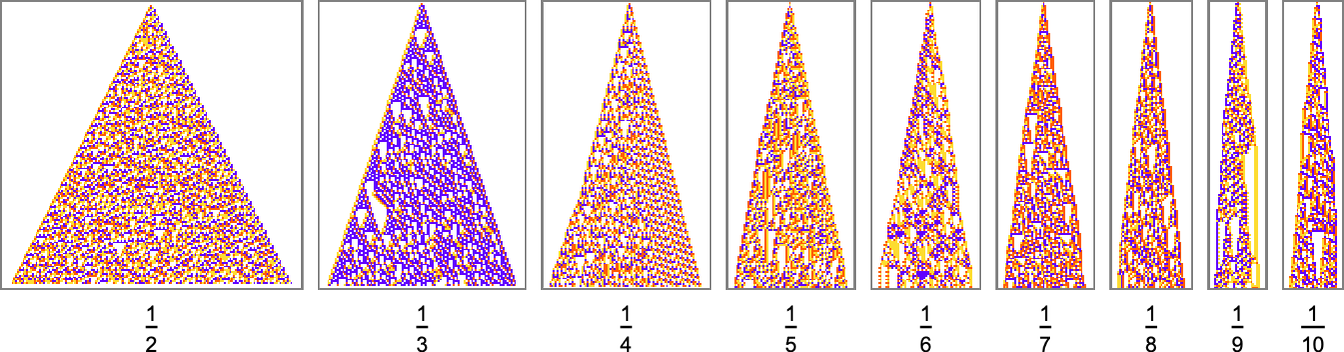
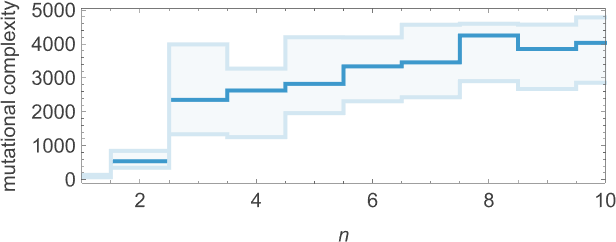
As we increase n we typically see that more steps of adaptive evolution are needed to achieve our goal, reflecting the idea that “larger n growth” has more mutational complexity:
For rational growth rates like ![]() fairly simple exact solutions are possible. But for irrational growth rates, that’s no longer true. Still, it turns out that adaptive evolution is in a sense strong enough—and our cellular automaton rule space is large enough—that good approximations even to irrational growth rates can often be reached:
fairly simple exact solutions are possible. But for irrational growth rates, that’s no longer true. Still, it turns out that adaptive evolution is in a sense strong enough—and our cellular automaton rule space is large enough—that good approximations even to irrational growth rates can often be reached:
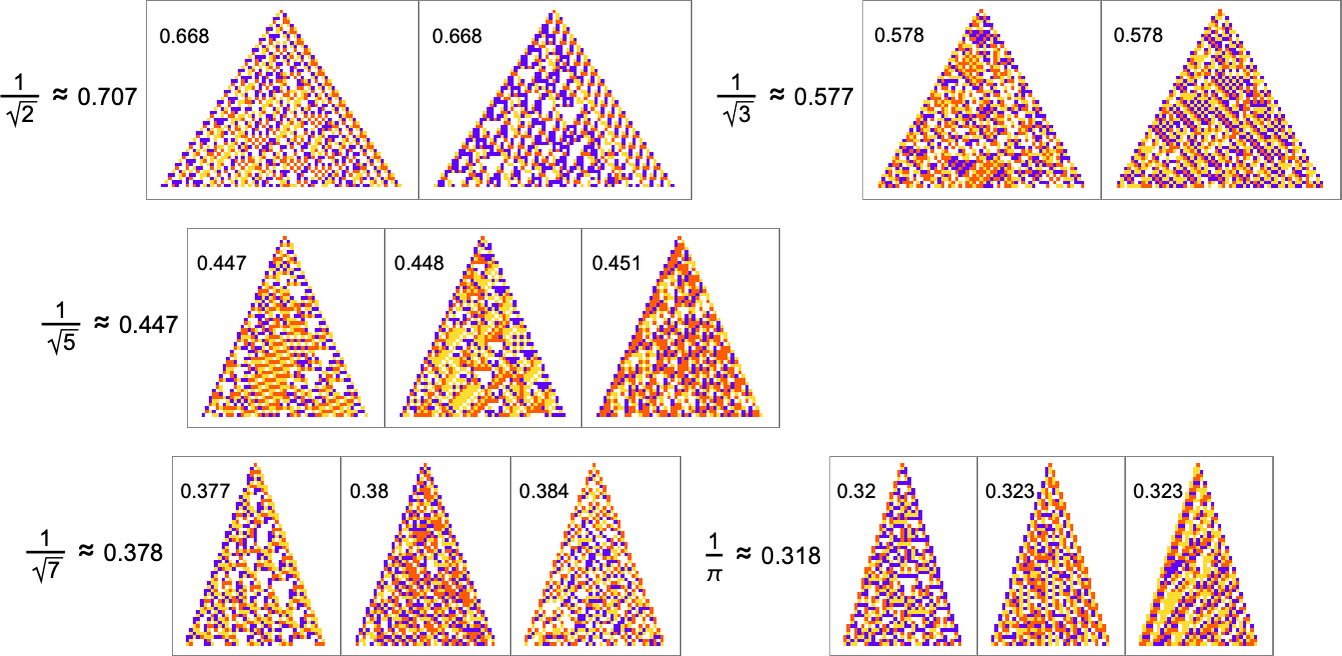
The “solutions” typically remain quite consistent when run longer:
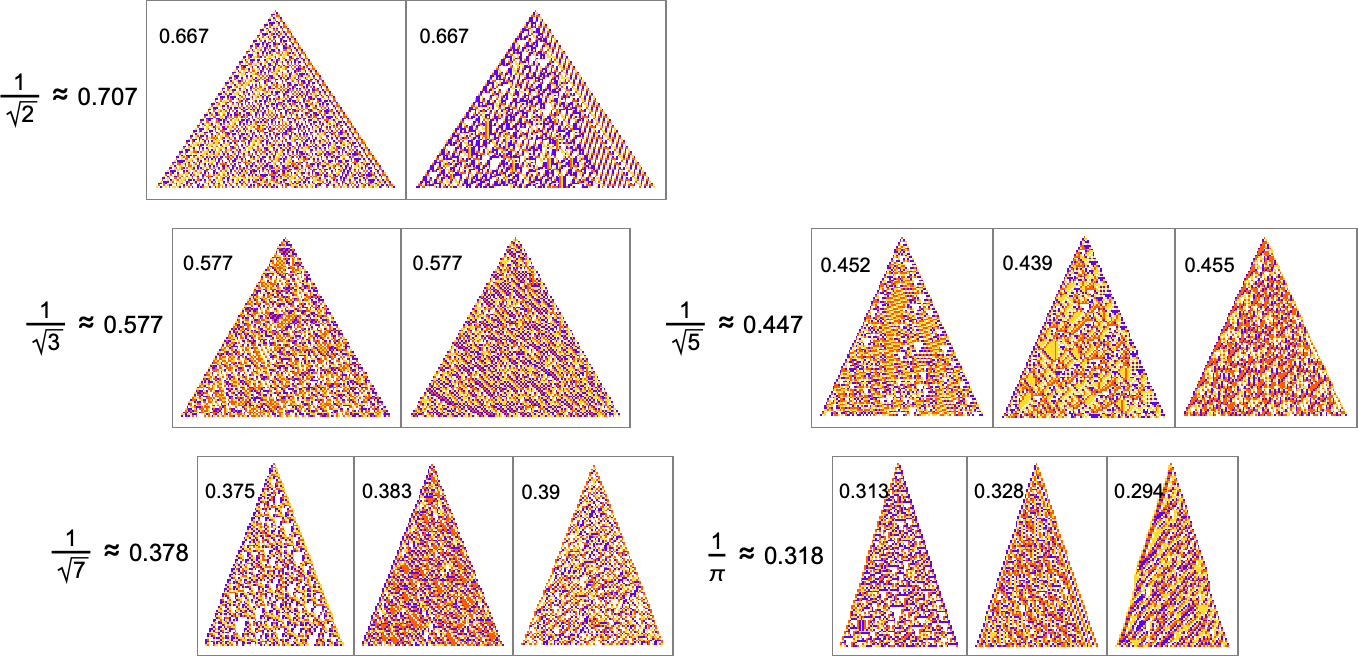
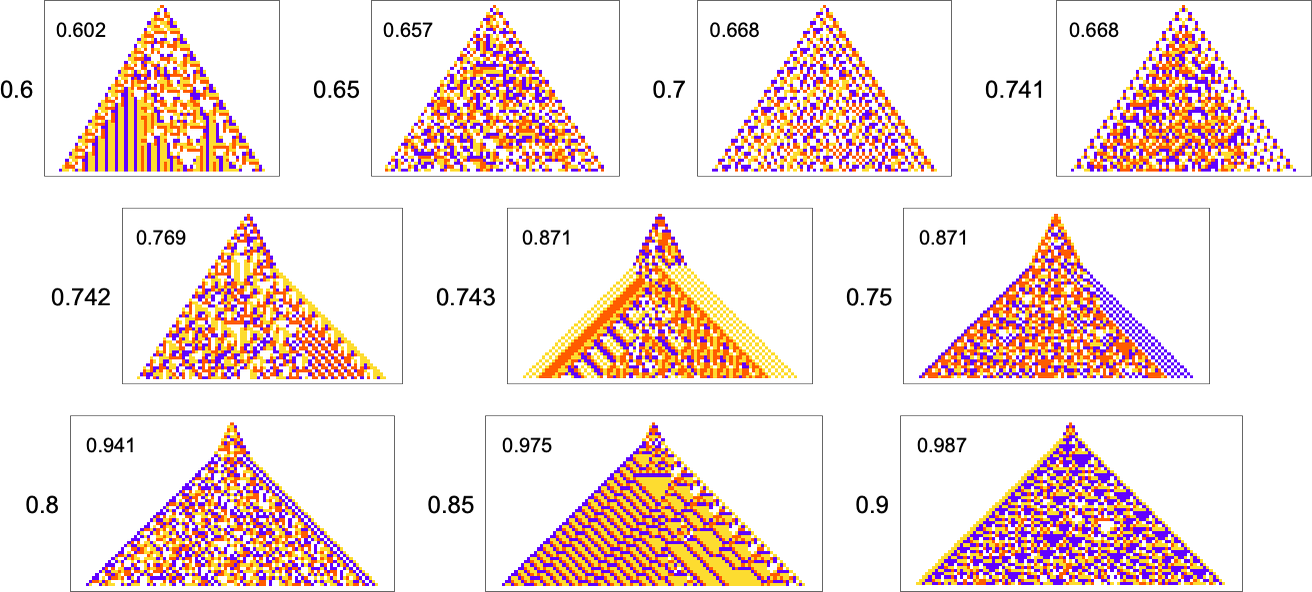
But there are still some notable limitations. For example, while a growth rate of exactly 1 is easy to achieve, growth rates close to 1 are in effect “structurally difficult”. For example, above about 0.741 adaptive evolution tends to “cheat”—adding a “hat” at the top of the pattern instead of actually producing a boundary with consistent slope:
What about other shapes as goals? Here’s what happens with diamond shapes of difficult widths:
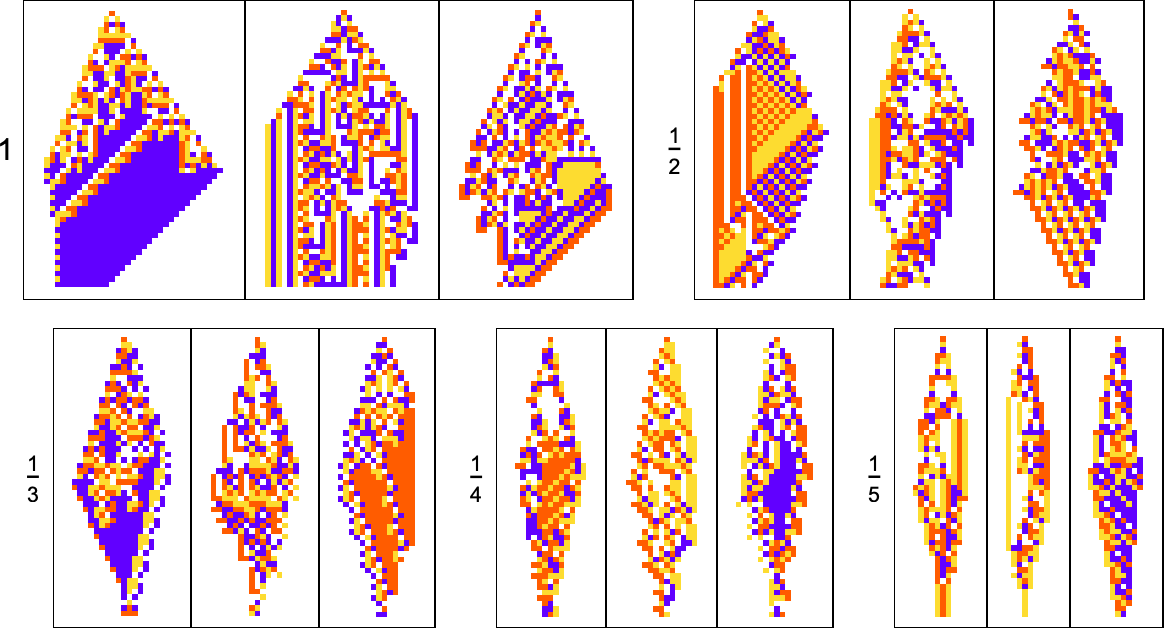
Adaptive evolution is quite constrained by what’s structurally possible in a cellular automaton of this type—and the results are not particularly good. And indeed if one attempts to “generalize” them, it’s clear none of them really “have the idea” of a diamond shape:

Lifetimes
In the examples we’ve discussed so far, we’ve focused on what cellular automata do over the course of a fixed number of steps—not worrying about what they might do later. But another goal we might have—which in fact I have discussed at length elsewhere—is just to have our cellular automata produce patterns that go for a certain number of steps and then die out. So, for example, we can use adaptive evolution to find cellular automata whose patterns live for exactly 50 steps, and then die out:
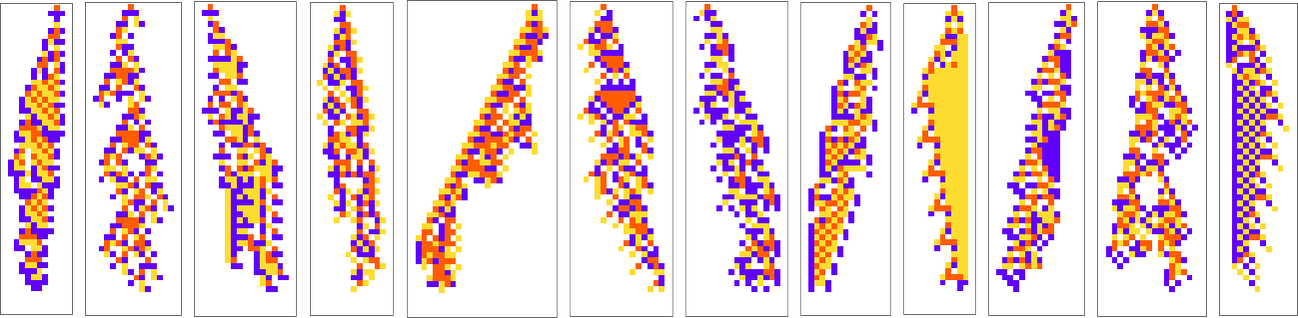
Just like in our other examples, adaptive evolution finds all sorts of diverse and “interesting” solutions to the problem of living for exactly 50 steps. Some (like the last one and the yellow one) have a certain level of “obvious mechanism” to them. But most of them seem to “just work” for no “obvious reason”. Presumably the constraint of living for 50 steps in some sense just isn’t stringent enough to “squeeze out” computational irreducibility—so there is still plenty of computational irreducibility in these results.
What about mutational complexity? Approximating this, as before, by the median of the number of adaptive evolution steps—and sampling a few hundred cases for each lifetime goal (and plotting the quartiles as well as the median)—we see a systematic increase of mutational complexity as we increase the lifetime goal:
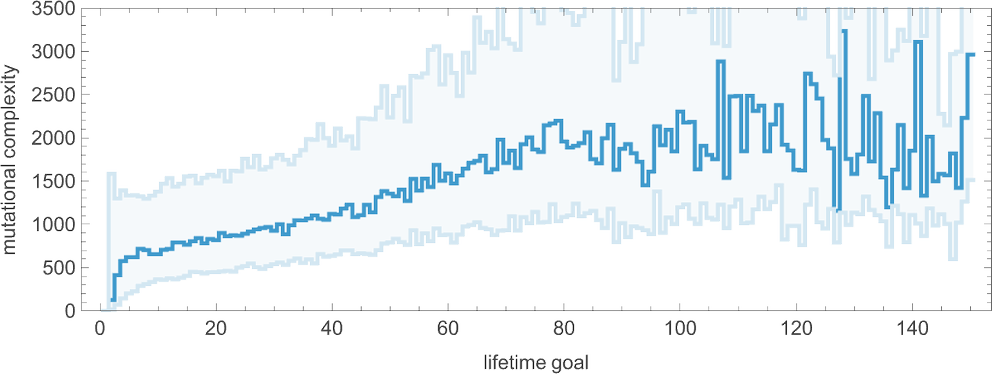
In effect this shows us that if we increase the lifetime goal, it becomes more and more difficult for adaptive evolution to reach that goal. (And, as we’ve discussed elsewhere, if we go far enough, we’ll ultimately reach the edge of what’s even in principle possible with, say, the particular type of 4-color cellular automata we’re using here.)
All the objectives we’ve discussed so far have the feature that they are in a sense explicit and fixed: we define what we want (e.g. a cellular automaton pattern that lives for exactly 50 steps) and then we use adaptive evolution to try to get it. But looking at something like lifetime suggests another possibility. Instead of our objective being fixed, our objective can instead be open ended. And so, for example, we might ask not for a specific lifetime, but to get the largest lifetime we can.
I’ve discussed this case at some length elsewhere. But how does it relate to the concept of the rulial ensemble that we’re studying here? When we have rules that are found by adaptive evolution with fixed constraints we end up with something that can be thought of as roughly analogous to things like the canonical (“specified temperature”) ensemble of traditional statistical mechanics. But if instead we look at the “winners” of open-ended adaptive evolution then what we have is more like a collection of extreme value than something we can view as typical of the “bulk of an ensemble”.
Periodicities
We’ve just looked at the goal of having patterns that survive for a certain number of steps. Another goal we can consider is having patterns that periodically repeat after a certain number of steps. (We can think of this as an extremely idealized analog of having multiple generations of a biological organism.)
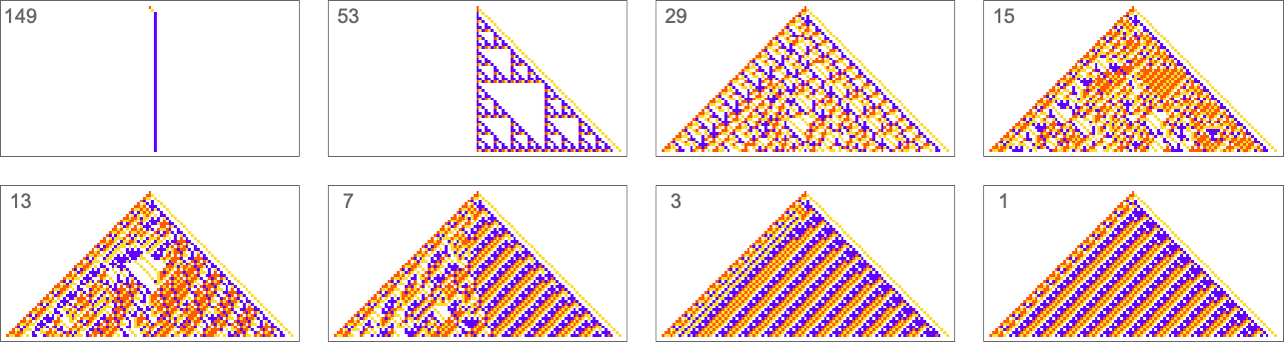
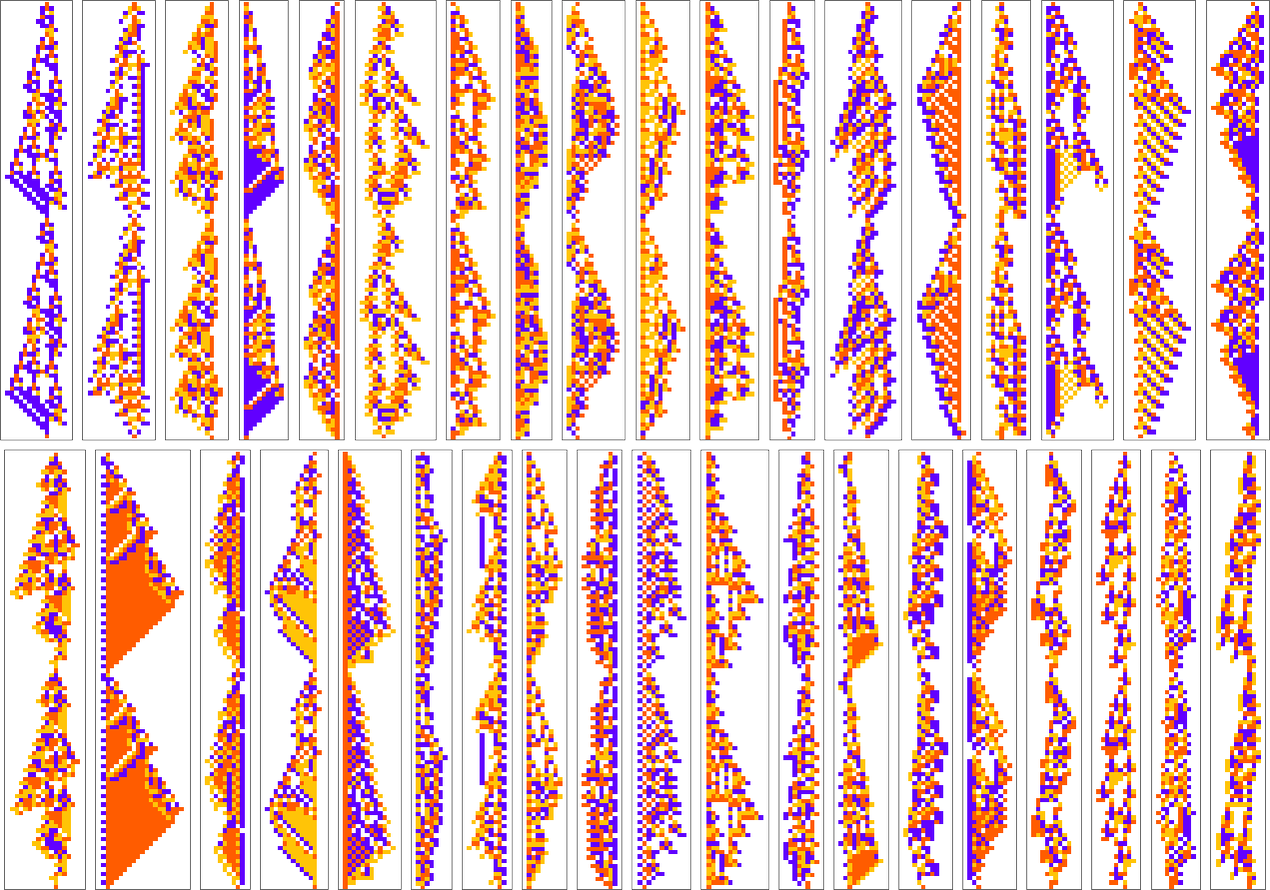
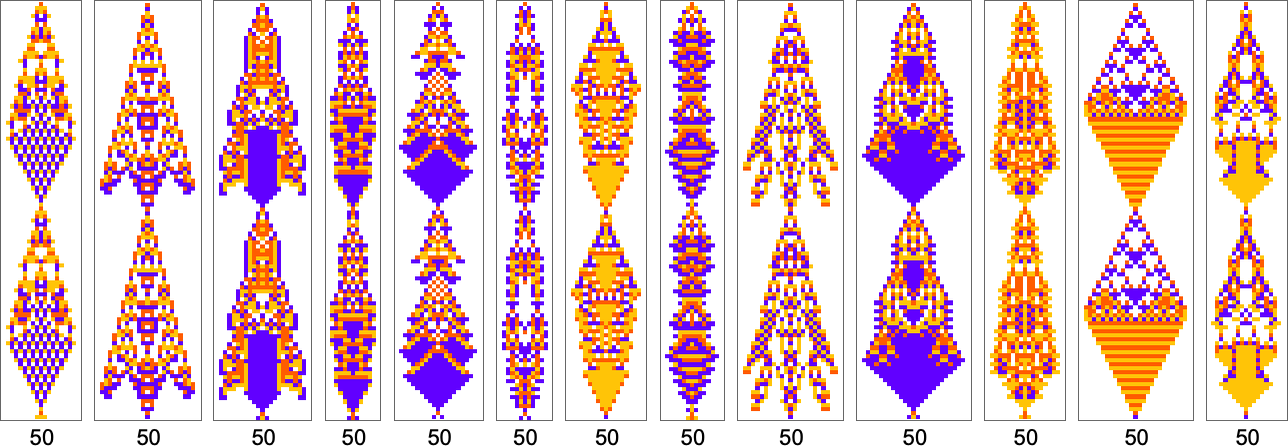
Here are examples of rules found by adaptive evolution that lead to patterns which repeat after exactly 50 steps:
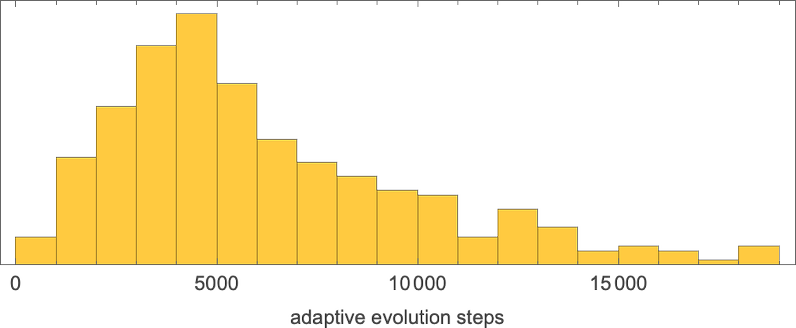
As usual, there’s a distribution in the number of steps of adaptive evolution required to achieve these results:
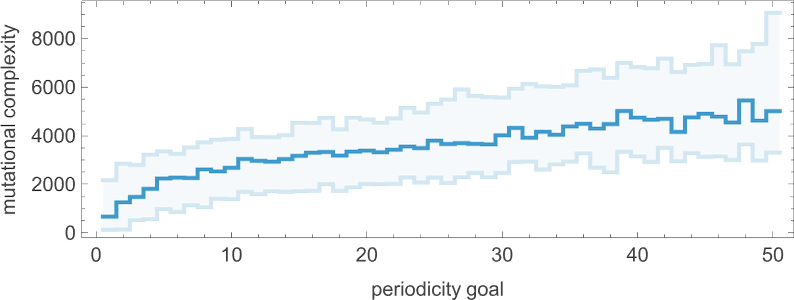
Looking at the median of the analogous distributions for different possible periods, we can get an estimate of the mutational complexity of different periods—which seems to increase somewhat uniformly with period:
By the way, it’s also possible to restrict our adaptive evolution so that it samples only symmetric rules; here are a few examples of period-50 results found in this way:
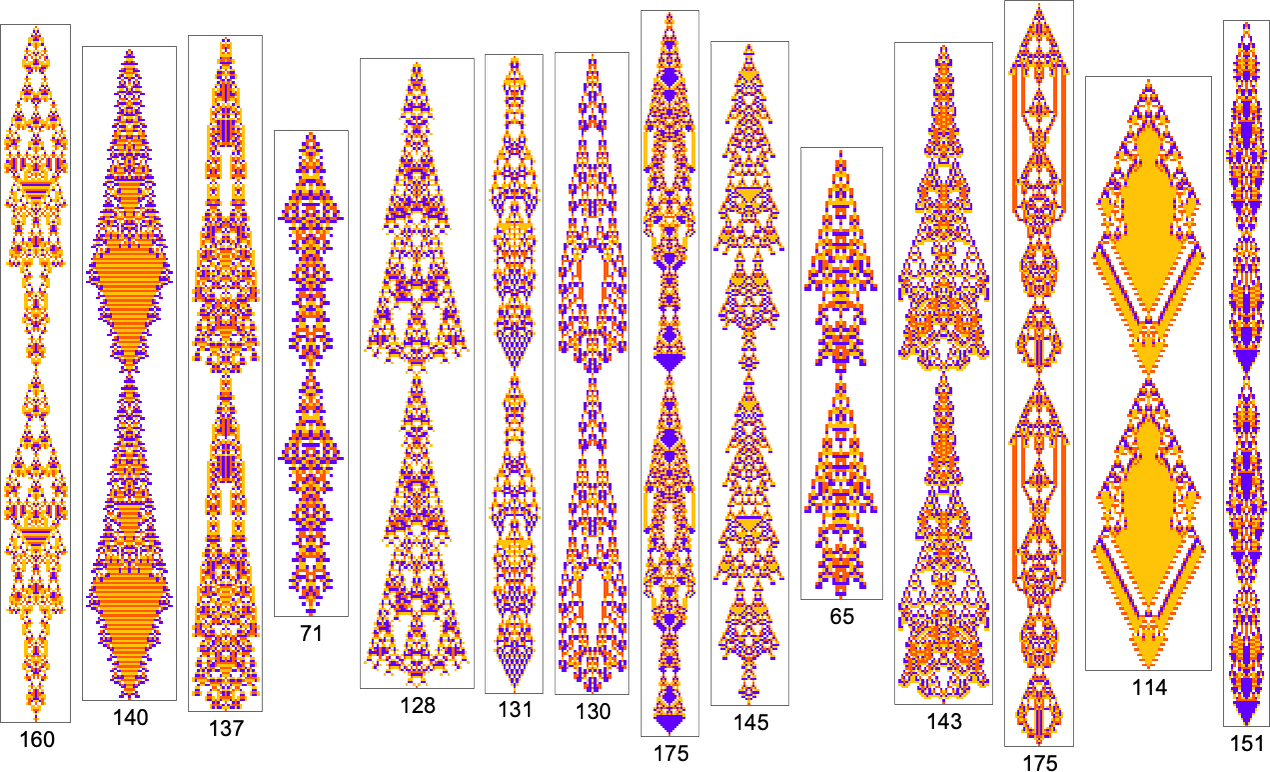
In our discussion of periodicity so far, we’ve insisted on “periodicity from the start”—meaning that after each period the pattern we get has to return to the single-cell state we started from. But we can also consider periodicity that “develops after a transient”. Sometimes the transient is short; sometimes it’s much longer. Sometimes the periodic pattern starts from a small “seed”; sometimes its seed is quite large. Here are some examples of patterns found by adaptive evolution that have ultimate period 50:

By the way, in all these cases the periodic pattern seems like the “main event” of the cellular automaton evolution. But there are other cases where it seems more like a “residue” from other behavior—and indeed that “other behavior” can in principle go on for arbitrarily long before finally giving way to periodicity:

We’ve been talking so far about the objective of finding cellular automaton rules that yield patterns with specific periodicity. But just like for lifetime, we can also consider the “open-ended objective” of finding rules with the longest periods we can. And here are the best results found with a few runs of 10,000 steps of adaptive evolution (here we’re looking for periodicity without transients):
Measuring Mechanoidal Behavior
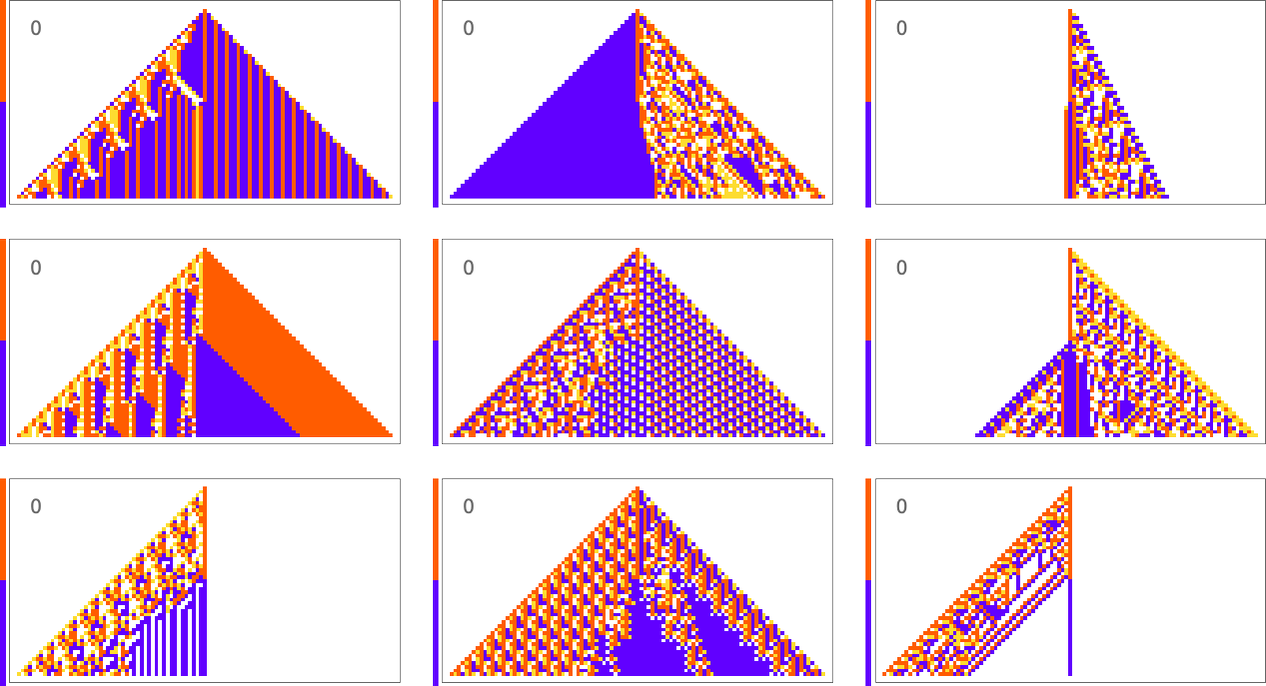
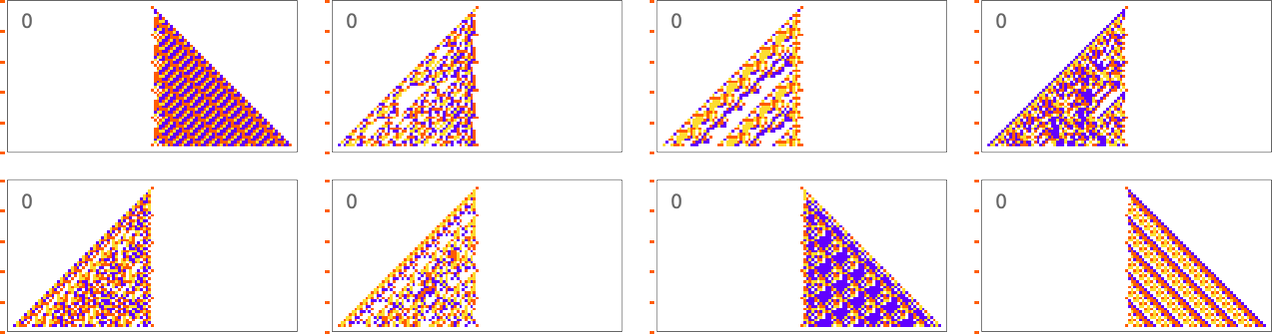
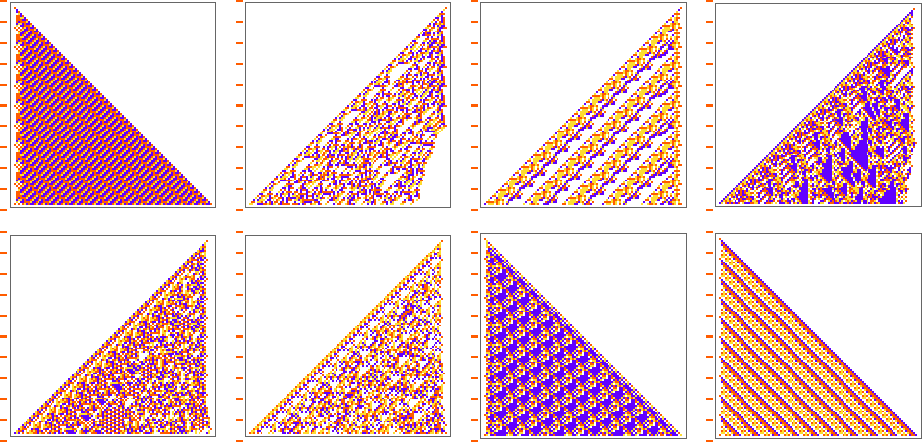
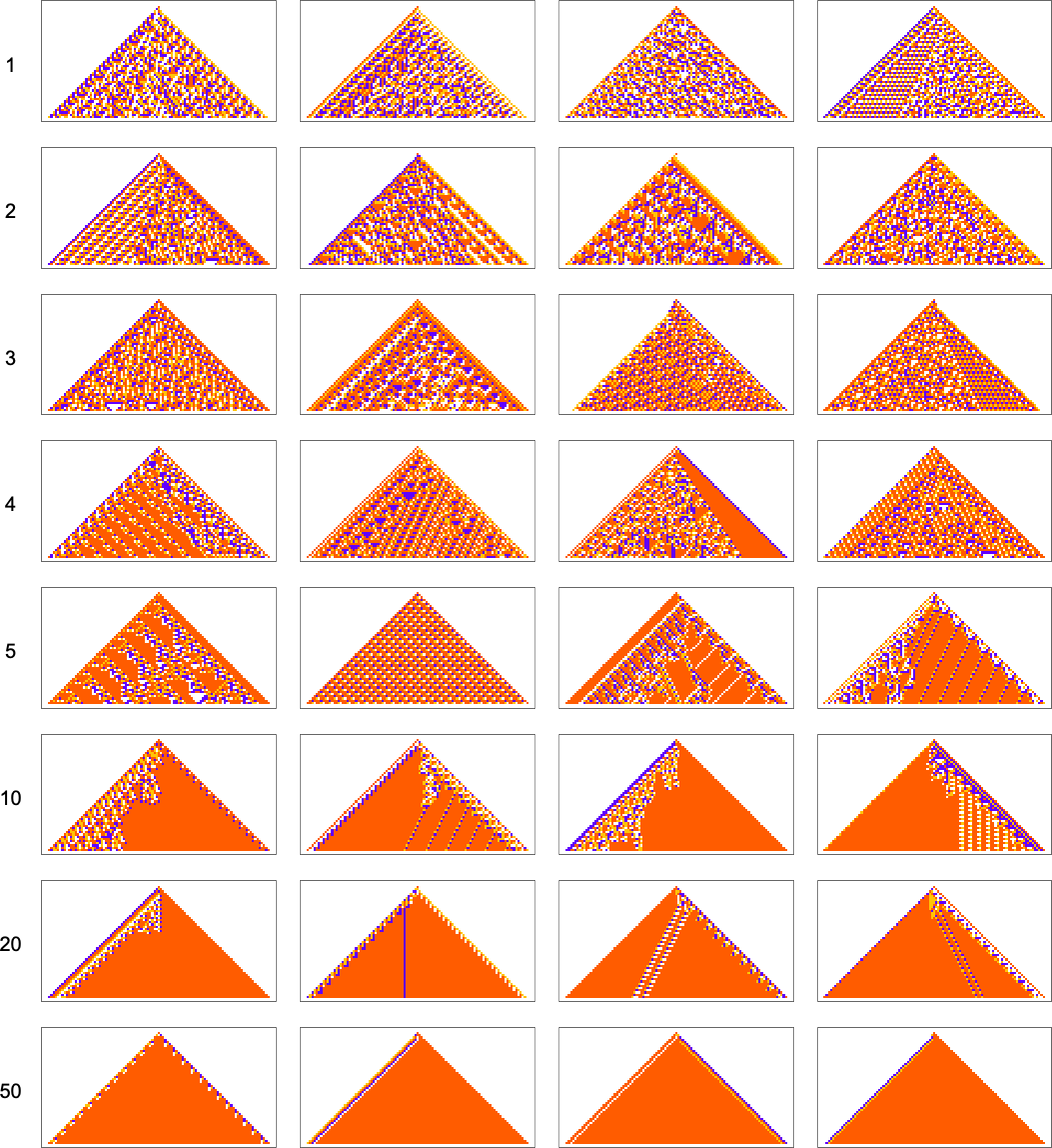
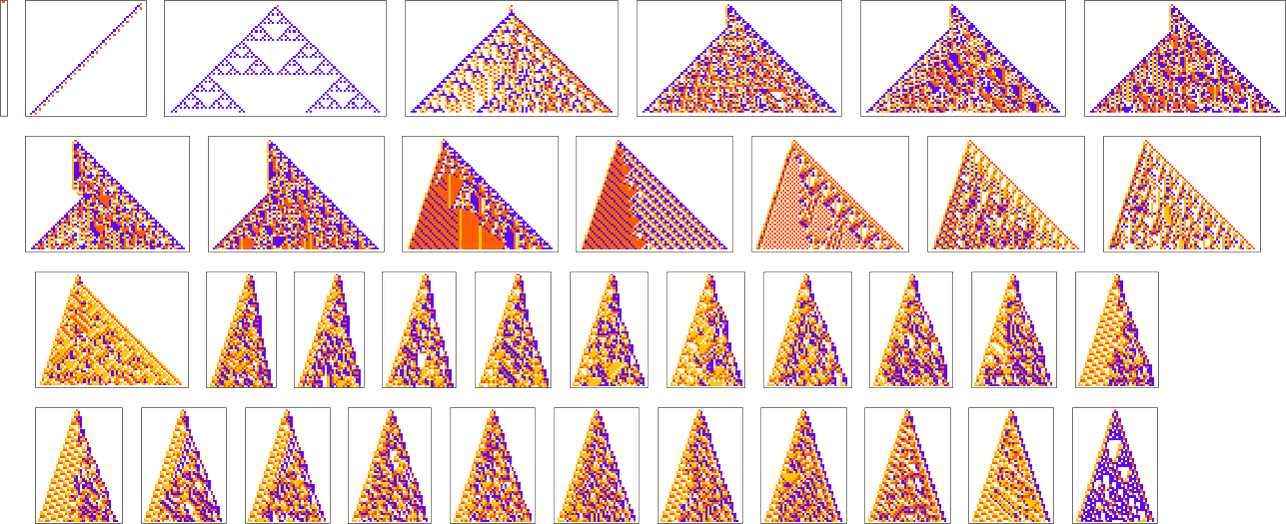
We’ve now seen lots of examples of cellular automata found by adaptive evolution. And a key question is: “what’s special about them?” If we look at cellular automata with rules chosen purely at random, here are typical examples of what we get:
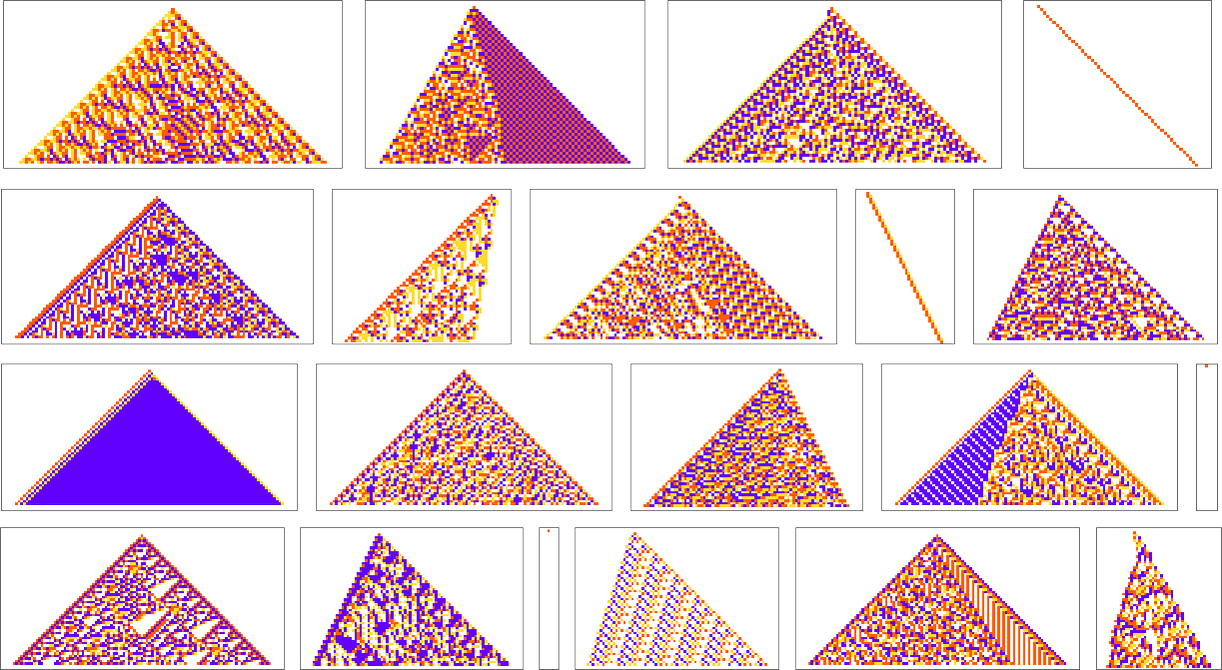
Some of these patterns are simple. But many are complicated and in fact look quite random—though often with regions or patches of regularity. But what’s striking is how visually different they look from what we’ve mostly seen above in cellular automata that were adaptively evolved “for a purpose”.
So how can we characterize—and ultimately measure—that difference? Our randomly picked cellular automata seem to show either almost total computational reducibility or “unchecked computational irreducibility” (albeit usually with regions or patches of computational reducibility). But cellular automata that were successfully “evolved for a purpose” tend to look different. They tend to show what we’re calling mechanoidal behavior: behavior in which there are identifiable “mechanism-like features”, albeit usually mixed in with at least some—typically highly contained—“sparks of computational irreducibility”.
At a visual level there are typically some clear characteristics to mechanoidal behavior. For example, there are usually repeated motifs that appear throughout a system. And there’s also usually a certain degree of modularity, with different parts of the system operating at least somewhat independently. And, yes, there’s no doubt a rich phenomenology of mechanoidal behavior to be studied (closely related to the study of class 4 behavior). But at a coarse and potentially more immediately quantitative level a key feature of mechanoidal behavior is that it involves a certain amount of regularity, and computational reducibility.
So how can one measure that? Whenever there’s regularity in a system it means there’s a way to summarize what the system does more succinctly than by just specifying every state of every element of the system. Or, in other words, there’s a way to compress our description of the system.
Perhaps, one might think, one could use modularity to do this compression, say by keeping only the modular parts of a system, and eliding away the “filler” in between—much like run-length encoding. But—like run-length encoding—the most obvious version of this runs into trouble when the “filler” consists, say, of alternating colors of cells. One can also think of using block-based encoding, or dictionary encoding, say leveraging repeated motifs that appear. But it’s an inevitable feature of computational irreducibility that in the end there can never be one universally best method of compression.
But as an example, let’s just use the Wolfram Language Compress function. (Using GZIP, BZIP2, etc. gives essentially identical results.) Feed in a cellular automaton pattern, and Compress will give us a (losslessly) compressed version of it. We can then use the length of this as a measure of what’s left over after we “compress out” the regularities in the pattern. Here’s a plot of the “compressed description length” (in “Compress output bytes”) for some of the patterns we’ve seen above:
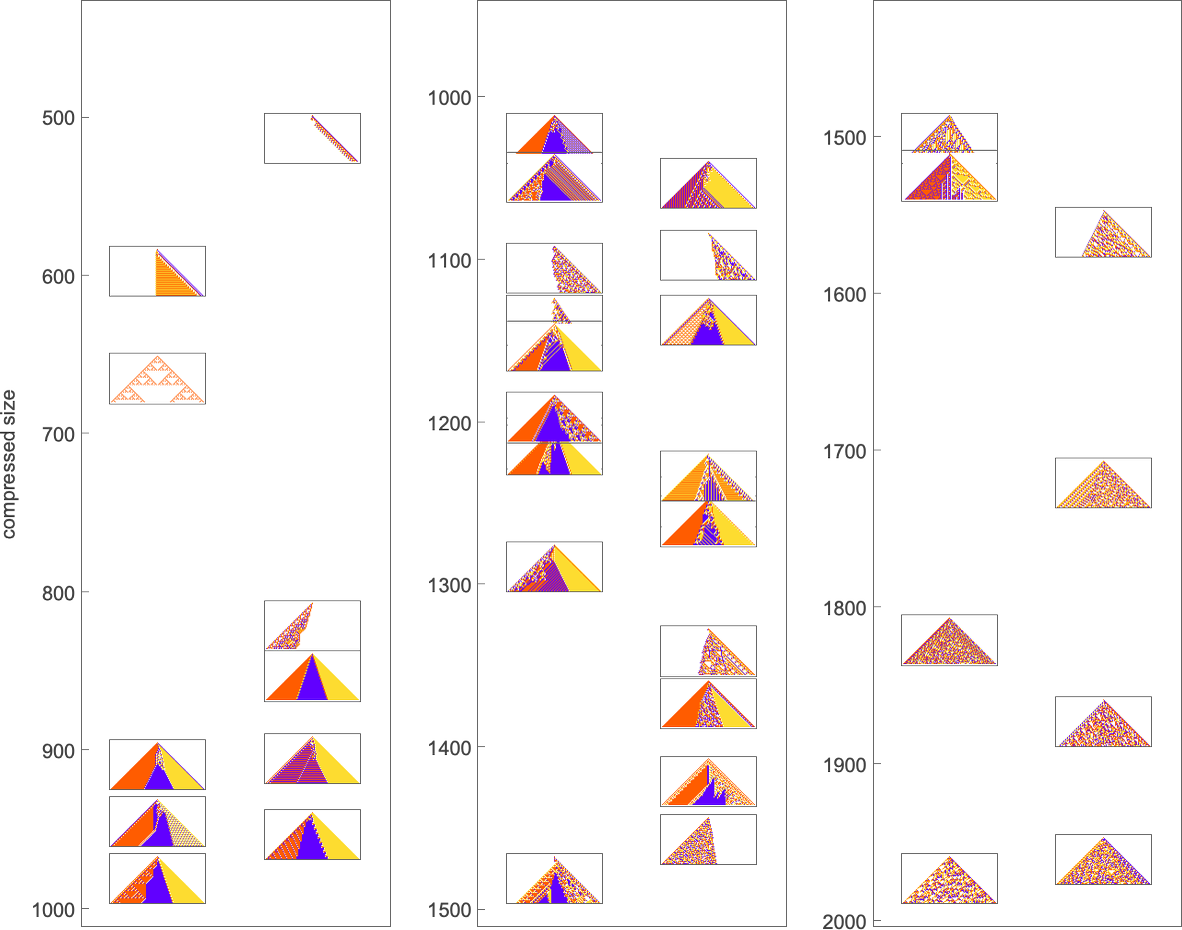
And what’s immediately striking is that the patterns “evolved for a purpose” tend to be in between patterns that come from randomly chosen rules.
(And, yes, the question of what’s compressed by what is a complicated, somewhat circular story. Compression is ultimately about making a model for things one wants to compress. And, for example, the appropriate model will change depending on what those things are. But for our purposes here, we’ll just use Compress—which is set up to do well at compressing “typical human-relevant content”.)
OK, so how does adaptive evolution relate to our “compressed size” measure? Here’s an example of the typical progression of an adaptive evolution process—in this case based on the goal of generating the ![]() sequence:
sequence:
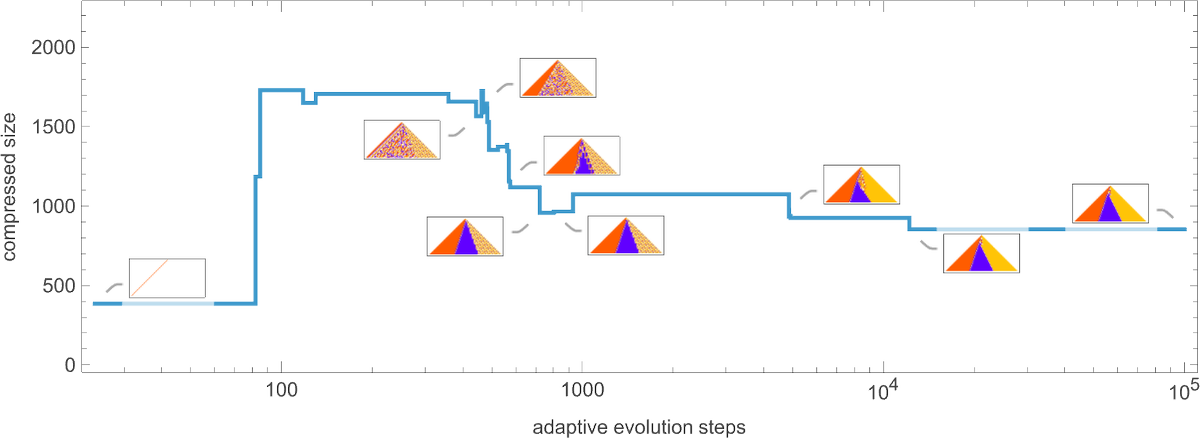
Given our way of starting with the null rule, everything is simple at the beginning—yielding a small compressed size. But soon the system starts developing computational irreducibility, and the compressed size goes up. Still, as the adaptive evolution proceeds, the computational irreducibility is progressively “squeezed out”—and the compressed size settles down to a smaller value.
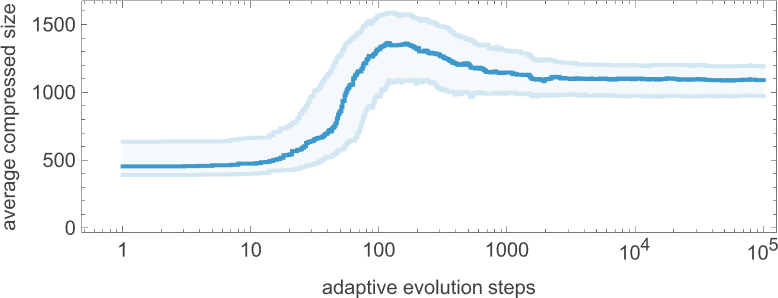
The plot above is based on a particular (randomly chosen) sequence of mutations in the underlying rule. But if we look at the average from a large collection of mutation sequences we see very much the same thing:
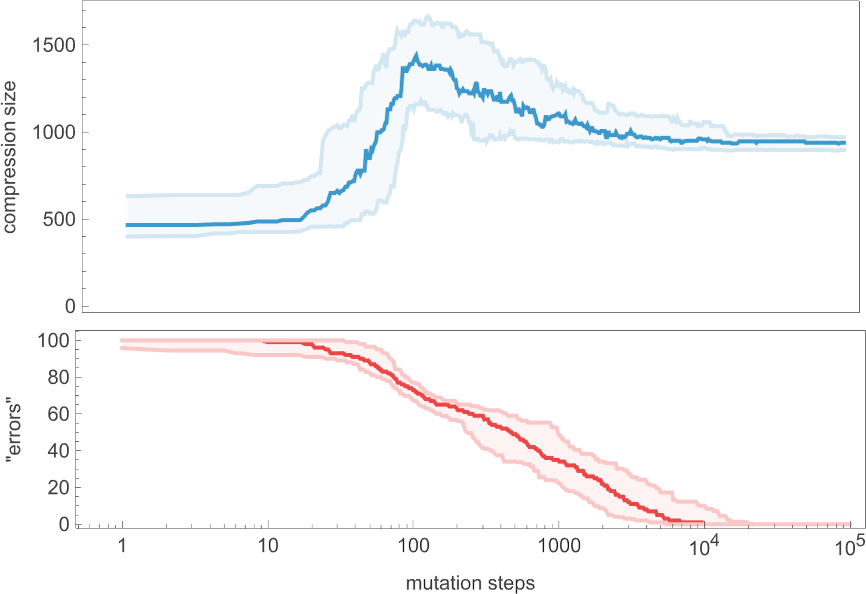
Even though the “error rate” on average goes down monotonically, the compressed size of our candidate patterns has a definite peak before settling to its final value. In effect, it seems that the system needs to “explore the computational universe” a bit before figuring out how to achieve its goal.
But how general is this? If we don’t insist on reaching zero error we get a curve of the same general shape, but slightly smoothed out (here for 20 or fewer errors):
What about for other target sequences? Here are results for all the target sequences we considered before (with the number of errors allowed in each case indicated):
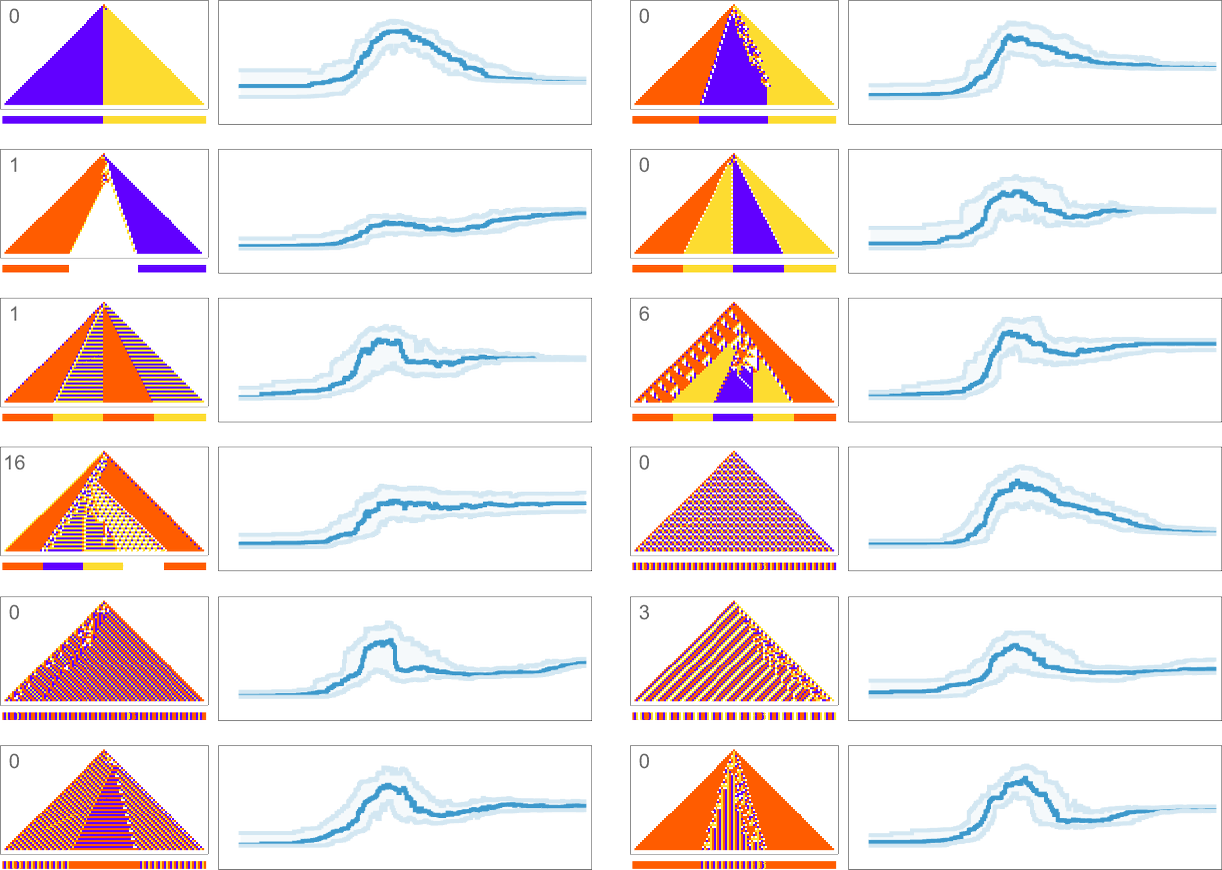
In all cases we get final compressed sizes that are much smaller than those for all-but-very-simple randomly chosen rules—indicating that our adaptive evolution process has indeed generated regularity, and our compression method has successfully picked this up.
Looking at the overall shape of the curves we’ve generated here, there seems to be a general phenomenon in evidence: the process of adaptive evolution seems to pass through a “computationally irreducible period” before getting to its final mechanoidal state. Even as it gets progressively closer to its goal, the adaptive evolution process ends up still “playing the field” before homing in on its “final solution”. (And, yes, phenomena like this are seen both in the fossil record of life on Earth and in the development of engineering systems.)
The Rulial Ensemble and Its Implications
We began by asking the question “what consequences does being ‘evolved for a purpose’ have on a system?” We’ve now seen many examples of different “purposes”, and how adaptive evolution can achieve them. The details are different in different cases. But we’ve seen that there are general features that occur very broadly. Perhaps most notable is that in systems that were “adaptively evolved for a purpose” one tends to see what we can call mechanoidal behavior: behavior in which there are “mechanism-like” elements.
Rules that are picked purely at random—in effect uniformly from rulial space—rarely show mechanoidal behavior. But in rules that have been adaptively evolved for a purpose mechanoidal behavior is the norm. And what we’ve found here is that this is true essentially regardless of what the specific purpose involved is.
We can think of rules that have been adaptively evolved for a purpose as forming what we can call a rulial ensemble: a subset of the space of all possible rules, concentrated by the process of adaptive evolution. And what we’ve seen here is that there are in effect generic features of the rulial ensemble—features that are generically seen in rules that have been adaptively evolved for a purpose.
Given a particular purpose (like “produce this specific sequence as output”) there are typically many ways it can be achieved. It could be that one can engineer a solution that shows a “human-recognizable mechanism” all the way through. It could be that it would be a “lump of computationally irreducible behavior” that somehow “just happens” to have the result of doing what we want. But adaptive evolution seems to produce solutions with what amount to intermediate characteristics. There are elements of mechanism to be seen. And there are also usually certain “sparks of computational irreducibility”. Typically what we see is that in the process of adaptive evolution all sorts of computational irreducibility is generated. But to achieve whatever purpose has been defined requires “taming” that irreducibility. And, it seems, introducing the kind of “patches of mechanism” that are characteristic of the mechanoidal behavior we have seen.
That those “patches of mechanism” fit together to achieve an overall purpose is often a surprising thing. But it’s the essence of the kind of “bulk orchestration” that we see in the systems we’ve studied here, and that seems also to be characteristic of biological systems.
Having specified a particular purpose it’s often completely unclear how a given kind of system could possibly achieve it. And indeed what we’ve seen adaptive evolution do here often seems like magic. But in a sense what we’re seeing is just a reflection of the immense power that is available in the computational universe, and manifest in the phenomenon of computational irreducibility. Without computational irreducibility we’d somehow “get what we expect”; computational irreducibility is what adds what is ultimately an infinite element of surprise. And what we’ve seen is that adaptive evolution manages to successfully harness that “element of surprise” to achieve particular purposes.
Let’s say our goal is to generate a particular sequence of values. One might imagine just operating on a space of possible sequences, and gradually adaptively evolving to the sequence we want. But that’s not the setup we’re using here, and it’s not the setup biology has either. Instead what’s happening both in our idealized cellular automaton systems—and in biology—is that the adaptive evolution process is operating at the level of underlying rules, but the purposes are achieved by the results of running those rules. And it’s because of this distinction—which in biology is associated with genotypes vs. phenotypes—that computational irreducibility has a way to insert itself. In some sense both the underlying rules and overall patterns of purposes can be thought of as defining certain “syntactic structures”. The actual running of the rules then represents what one can think of as the “semantics” of the system. And it’s there that the power of computation is injected.
But in the end, just how powerful is adaptive evolution, with its ability to tap into computational irreducibility, and to “mine” the computational universe? We’ve seen that some goals are easier to reach than others. And indeed we introduced the concept of mutational complexity to characterize just how much “effort of adaptive evolution” (and, ultimately, how many mutations)—is needed to achieve a given objective.
If adaptive evolution is able to “fully run its course” then we can expect it to achieve its objective through rules that show mechanoidal behavior and clear “evidence of mechanism”. But if the amount of adaptive evolution stops short of what’s defined by the mutational complexity of the objective, then one’s likely to see more of the “untamed computational irreducibility” that’s characteristic of intermediate stages of adaptive evolution. In other words, if we “get all the way to a solution” there’ll be mechanism to be seen. But if we stop short, there’s likely to be all sorts of “gratuitous complexity” associated with computational irreducibility.
We can think of our final rulial ensemble as consisting of rules that “successfully achieve their purpose”; when we stop short we end up with another, “intermediate” rulial ensemble consisting of rules that are merely on a path to achieve their purpose. In the final ensemble the forces of adaptive evolution have in a sense tamed the forces of computational irreducibility. But in the intermediate ensemble the forces of computational irreducibility are still strong, bringing the various universal features of computational irreducibility to the fore.
It may be useful to contrast all of this with what happens in traditional statistical mechanics, say of molecules in a gas—in which I’ve argued (elsewhere) that there’s in a sense almost always “unchecked computational irreducibility”. And it’s this unchecked computational irreducibility that leads to the Second Law—by producing configurations of the system that we (as computationally bounded observers) can’t distinguish from random, and can therefore reasonably model statistically just as being “typical of the ensemble”, where now the ensemble consists of all possible configurations of the system that, for example, have the same energy or the same temperature. Adaptive evolution is a different story. First, it’s operating not directly on the configurations of a system, but rather on the underlying rules for the system. And second, if one takes the process of adaptive evolution far enough (so that, for example, the number of steps of adaptive evolution is large compared to the mutational complexity of the goal one’s pursuing), then adaptive evolution will “tame” the computational irreducibility. But there’s still an ensemble involved—though now it’s an ensemble of rules rather than an ensemble of configurations. And it’s not an ensemble that somehow “covers all rules”; rather, it’s an ensemble that is “sculpted” by the constraint of “achieving a purpose”.
I’ve argued that it’s the characteristics of “observers like us” that ultimately lead to the perceived validity of the Second Law. So is there a role for the notion of an observer in our discussion here of bulk orchestration and the rulial ensemble? Well, yes. And in particular it’s critical in grounding our concept of “purpose”. We might ask: what possible “purposes” are there? Well, for something to be a reasonable “purpose” there has to be some way to decide whether or not it’s been achieved. And to make such a decision we need something that’s in effect an “observer”.
In the case of statistical mechanics and the Second Law—and, in fact, in all our recent successes in deriving foundational principles in both physics and mathematics—we want to consider observers that are somehow “like us”, because in the end what matters for us is how we as observers perceive things. I’ve argued that the most critical feature of observers like us is that we’re computationally bounded (and also, somewhat relatedly, that we assume we’re persistent in time). And it then turns out that the interplay of these features with underlying computational irreducibility is what seems to lead to the core principles of physics (and mathematics) that we’re familiar with.
But what should we assume about the “observer”—or the “determiner of purpose”—in adaptive evolution, and in particular in biology? It turns out that once again it seems as if computational boundedness is the key. In biological evolution, the implicit “goal” is to have a successful (or “fit”) organism that will, for example, reproduce well in its environment. But the point is that this is a coarse constraint—that we can think of at a computational level as being computationally bounded.
And indeed I’ve recently argued that it’s this computational boundedness that’s ultimately responsible for the fact that biological evolution can work at all. If to be successful an organism always immediately had to satisfy some computationally very complex constraint, adaptive evolution wouldn’t typically ever be able to find the necessary “solution”. Or, put another way, biological evolution works because the objectives it ends up having to achieve are of limited mutational complexity.
But why should it be that the environment in which biological evolution occurs can be “navigated” by satisfying computational bounded constraints? In the end, it’s a consequence of the inevitable presence of pockets of computational reducibility in any ultimately computationally irreducible system. Whatever the underlying structure of things, there will always be pockets of computational reducibility to be found. And it seems that that’s what biology and biological evolution rely on. Specific types of biological organisms are often thought of as populating particular “niches” in the environment defined by our planet; what we’re saying here is that all possible “evolved entities” populate an abstract “meta niche” associated with possible pockets of computational reducibility.
But actually there’s more. Because the presence of pockets of computational reducibility is also what ultimately makes it possible for there to be observers like us at all. As I’ve argued elsewhere, it’s an abstract necessity that there must exist a unique object—that I call the ruliad—that is the entangled limit of all possible computational processes. And everything that exists must somehow be within the ruliad. But where then are we? It’s not immediately obvious that observers like us—with a coherent existence—would be possible within the ruliad. But if we are to exist there, we must in effect exist in some computationally reducible slice of the ruliad. And, yes, for us to be the way we are, we must in effect be in such a slice.
But we can still ask why and how we got there. And that’s something that’s potentially informed by the notion of adaptive evolution that we’ve discussed here. Indeed, we’ve argued that for adaptive evolution to be successful its objectives must in effect be computationally reducible. So as soon as we know that adaptive evolution is operating it becomes in a sense inevitable that it will lead to pockets of computational reducibility. That doesn’t in and of itself explain why adaptive evolution happens—but in effect it shows that if it does, it will lead to observers that at some level have characteristics like us. So then it’s a matter of abstract scientific investigation to show—as we in effect have here—that within the ruliad it’s at least possible to have adaptive evolution.
Purpose vs. Mechanism and the Nature of Life
Any phenomenon can potentially be explained both in terms of purpose and in terms of mechanism. Why does a projectile follow that trajectory? One can explain it as following the mechanism defined by its laws of motion. Or one can explain it as following the purpose of satisfying some overall variational principle (say, extremizing the action associated with the trajectory). Sometimes phenomena are more conveniently explained in terms of mechanism; sometimes in terms of purpose. And one can imagine that the choice could be determined by which is somehow the “computationally simpler” explanation.
But what about the systems and processes we’ve discussed here? If we just run a system like a cellular automaton we always know its “mechanism”—it’s just its underlying rules. But we don’t immediately know its “purpose”, and indeed if we pick an arbitrary rule there’s no reason to think it will have a “computationally simple” purpose. In fact, insofar as the running of the cellular automaton is a computationally irreducible process, we can expect that it won’t “achieve” any such computationally simple purpose that we can identify.
But what if the rule is determined by some process of adaptive evolution? Well, then the objective of that adaptive evolution can be seen as defining a purpose that we can use to describe at least certain aspects of the behavior of the system. But what exactly are the implications of the “presence of purpose” on how the system operates? The key point that’s emerged here is that when there’s a computationally simple purpose that’s been achieved through a process of adaptive evolution, then the rules for the system will be part of what we’ve called the rulial ensemble. And then what we’ve argued is that there are generic features of the rulial ensemble—features that don’t depend on what specific purpose the adaptive evolution might have achieved, only that its purpose was computationally simple. And foremost among these generic features is the presence of mechanoidal behavior.
In other words, so long as there is an overall computationally simple purpose, what we’ve found is that—whatever in detail that purpose might have been—the presence of purpose tends to “push itself down” to produce behavior that locally is mechanoidal, in the sense that it shows evidence of “visible mechanism”. What do we mean by “visible mechanism”? Operationally, it tends to be mechanism that’s readily amenable to “human-level narrative explanation”.
It’s worth remembering that at the lowest level the systems we’ve studied are set up to have simple “mechanisms” in the sense that they have simple underlying rules. But once these rules run they generically produce computationally irreducible behavior that doesn’t have a simple “narrative-like” description. But when we’re looking at the results of adaptive evolution we’re dealing with a subset of rules that are part of the rulial ensemble—and so we end up seeing mechanoidal behavior with at least local “narrative descriptions”.
As we’ve discussed, though, if the adaptive evolution hasn’t “entirely run its course”, in the sense that the mutational complexity of the objective is higher than the actual amount of adaptive evolution that’s been done, then there’ll still be computational irreducibility that hasn’t been “squeezed out”.
So how does all this relate to biology? The first key element of biology as far as we are concerned here is that there’s a separate genotype and phenotype—related by what’s presumably in general the computationally irreducible process of biological growth, etc. The second key element of biology for our purposes here is the phenomenon of self reproduction—in which new organisms are produced with genotypes that are identical up to small mutations. Both these elements are immediately captured by the simple cellular automaton model we’ve used here.
And given them, we seem to be led inexorably to our conclusions here about the rulial ensemble, mechanoidal behavior, and bulk orchestration.
It’s often been seen as mysterious how there ends up being so much apparent complexity in biology. But once one knows about computational irreducibility, one realizes that actually complexity is quite ubiquitous. And instead what’s in many respects more surprising is the presence of any “explainable mechanism”. But what we’ve seen here through the rulial ensemble is that such explainable mechanism is in effect a shadow of overall “simple computational purposes”.
At some level there’s computational irreducibility everywhere. And indeed it’s
the driver for rich behavior. But what happens is that “in the presence of overall purpose”, patches of computational irreducibility have to be fitted together to achieve that purpose. Or, in other words, there’s inevitably a certain “bulk orchestration” of all those patches of computation. And that’s what we see so often in actual biological systems.
So what is it in the end that’s special about life—and biological systems? I think—more than anything—it’s that it’s involved so much adaptive evolution. All those ~1040 individual organisms in the history of life on earth have been links in chains of adaptive evolution. It might have been that all that “effort of adaptive evolution” would have the effect of just “solving the problem”—and producing some “simple mechanistic solution”.
But that’s not what we’ve seen here, and that’s not how we can expect things to work. Instead, what we have is an elaborate interplay of “lumps of computational irreducibility” being “harnessed” by “simple mechanisms”. It matters that there’s been so much adaptive evolution. And what we’re now seeing throughout biology—down to the smallest features—is the consequences of that adaptive evolution. Yes, there are “frozen accidents of history” to be seen. But the point is not those individual items, but rather the whole aggregate consequence of adaptive evolution: mechanoidal behavior and bulk orchestration.
And it’s because these features are generic that we can hope they can form the basis for what amounts to a robust “bulk” theory of biological systems and biological behavior: something that has roughly the same “bulk theory” character as the gas laws, or fluid dynamics. But that’s now talking about systems that have been subject to large-scale adaptive evolution at the level of their rules.
What I’ve done here is very much just a beginning. But I believe the ruliological investigations I’ve shown, and the general framework I’ve described, provide the raw material for something we’ve never had before: a well defined and general “fundamental theory” for the operation of living systems. It won’t describe all the “historical accident” details. But I’m hopeful that it will provide a useful global view of what’s going on, that can potentially be harvested for answers to all sorts of useful questions about the remarkable phenomenon we call life.
Appendix: Different Adaptive Strategies
In our explorations of the rulial ensemble—and of mutational complexity—we’ve looked at a range of possible objective functions. But we’ve always considered just one adaptive evolution strategy: accepting or rejecting the results of single-point random mutations in the rule at each step. So what would happen if we were to adopt a different strategy? The main conclusion is: it doesn’t seem to matter much. For a particular objective function, there are adaptive evolution strategies that get to a given result in fewer adaptive steps, or that ultimately get further than our usual strategy ever does. But in the end the basic story of the rulial ensemble—and of mutational complexity—is robust relative to detailed changes in our adaptive evolution process.
As an example, consider allowing more than one random mutation in the rule at each adaptive evolution step. Let’s say—as at the very beginning above—that our objective is to generate ![]() after 50 steps. With just one mutation at each step it’s only a small fraction of adaptive evolution “runs” that reach “perfect solutions”, but with more mutations at each step, more progress is made, at least in this case—as illustrated by histograms of the “number of errors” remaining after 10,000 adaptive evolution steps:
after 50 steps. With just one mutation at each step it’s only a small fraction of adaptive evolution “runs” that reach “perfect solutions”, but with more mutations at each step, more progress is made, at least in this case—as illustrated by histograms of the “number of errors” remaining after 10,000 adaptive evolution steps:

Looked at in terms of multiway systems, having fewer mutations at each step leads to fewer paths between possible rules, and a greater possibility of “getting stuck”. With more mutations at each step there are more paths overall, and a lower possibility of getting stuck.
So what about mutational complexity? If we still say that each adaptive evolution step accounts for a single unit of mutational complexity (even if it involves multiple underlying mutations in the rule), this shows how the mutational complexity (as computed above) for different objectives is affected by having different numbers of underlying mutations at each step (the height of each “tick” indicates the number of mutations):
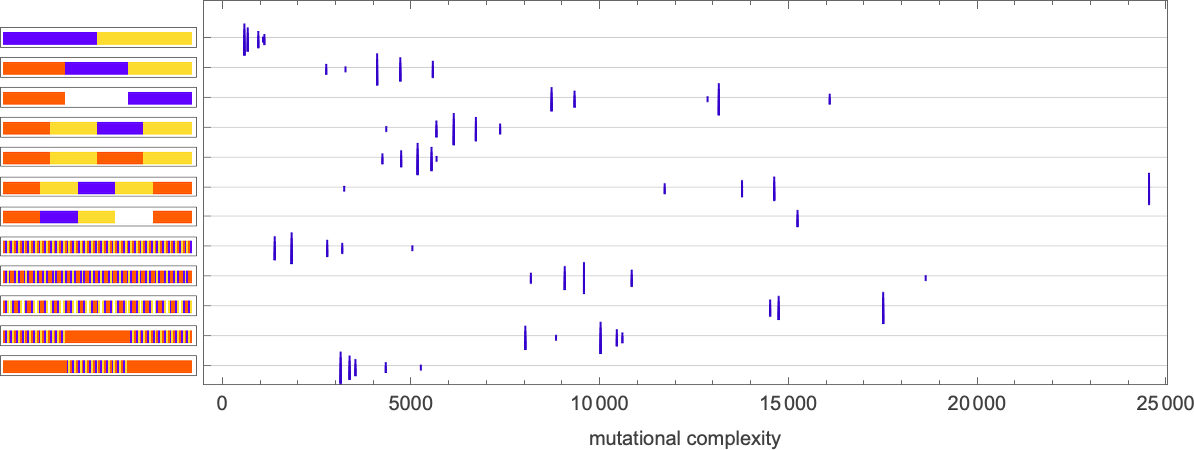
So, yes, different numbers of mutations at each step lead to mutational complexities that are different in detail, but in most cases, surprisingly similar overall.
What about other adaptive evolution strategies? There are many one could consider. For example, a “gradient descent” approach where at each step we examine all possible mutations, and pick the “best one”—i.e. the one that increases fitness the most. (We can extend this by keeping not just the top rule at each step, but, say, the top 5—in an analog of “beam search”.) There’s also a “collaborative” approach, where multiple different “paths” of random mutations are followed, but where every so often all are reset to be the best found so far. And indeed, we can consider all sorts of techniques from reinforcement learning.
In particular cases, any of these approaches can have significant effects. But in general the phenomena we’re discussing here seem robust enough that the details of how adaptive evolution is done don’t matter much, and the single-mutation strategy we’ve mostly used here can be considered adequately representative.
Historical & Personal Background
It’s been obvious since antiquity that living organisms contain some kind of “gooey stuff” that’s different from what one finds elsewhere in nature. But what is it? And how universal might it be? In Victorian times it had various names, the most notable being “protoplasm”. The increasing effectiveness of microscopy made it clear that there was actually a lot of structure in “living matter”—as, for example, reflected in the presence of different organelles. But until the later part of the twentieth century there was a general belief that fundamentally what was going on in life was chemistry—or at least biochemistry—in which all sorts of different kinds of molecules were randomly moving and undergoing chemical reactions at certain rates.
The digital nature of DNA discovered in 1953 slowly began to erode this picture, adding in ideas about molecular-scale mechanisms and “machinery” that could be described in mechanical or informational—rather than “bulk statistical”—ways. And indeed a notable trend in molecular biology over the past several decades has been the discovery of more and more ways in which molecular processes in living systems are “actively orchestrated”, and not just the result of “random statistical behavior”.
When a single component can be identified (cell membranes, microtubules, biomolecular condensates, etc.) there’s quite often been “bulk theory” developed, typically based on ideas from statistical mechanics. But when it comes to constellations of different kinds of components, most of what’s been done has been to collect the material to fill many volumes of biology texts with what amount to narrative descriptions of how in detail things operate—with no attempt at any kind of “general picture” independent of particular details.
My own foundational interest in biology goes back about half a century. And when I first started studying cellular automata at the beginning of the 1980s I certainly wondered (as others had before) whether they might be relevant to biology. That question was then greatly accelerated when I discovered that even with simple rules, cellular automata could generate immensely complex behavior, which often looked visually surprisingly “organic”.
In the 1990s I put quite some effort into what amount to macroscopic questions in biology: how do things grow into different shapes, produce different pigmentation patterns, etc.? But somehow in everything I studied there was a certain assumed uniformity: many elements might be involved, but they were all somehow essentially the same. I was well aware of the complex reaction networks—and, later, pieces of “molecular machinery”—that had been discovered. But they felt more like systems from engineering—with lots of different detailed components—and not like systems where there could be a “broad theory”.
Still, within the type of engineering I knew best—namely software engineering—I kept wondering whether there might perhaps be general things one could say, particularly about the overall structure and operation of large software systems. I made measurements. I constructed dependency graphs. I thought about analogies between bugs and diseases. But beyond a few power laws and the like, I never really found anything.
A lot changed, however, with the advent of our Physics Project in 2020. Because, among other things, there was now the idea that everything—even the structure of spacetime—was dynamic, and in effect emerged from a graph of causal relationships between events. So what about biology? Could it be that what mattered in molecular biology was the causal graph of interactions between individual molecules? Perhaps there needed to be a “subchemistry” that tracked specific molecules, rather than just molecular species. And perhaps to imagine that ordinary chemistry could be the basis for biology was as wide of the mark as thinking that studying the physics of electron gases would let one understand microprocessors.
Back in the early 1980s I had identified that the typical behavior of systems like cellular automata could be divided into four classes—with the fourth class having the highest level of obvious complexity. And, yes, the visual patterns produced in class 4 systems often had a very “life like” appearance. But was there a foundational connection? In 2023, as part of closing off a 50-year personal journey, I had been studying the Second Law of thermodynamics, and identified class 4 systems as ones that—like living systems—aren’t usefully described just in terms of a tendency to randomization. Reversible class 4 systems made it particularly clear that in class 4 there really was a distinct form of behavior—that I called “mechanoidal”—in which a certain amount of definite structure and “mechanism” are visible, albeit embedded in great overall complexity.
At first far from thinking about molecules I made some surprise progress in 2024 on biological evolution. In the mid-1980s I had considered modeling evolution in terms of successive small mutations to things like cellular automaton rules. But at the time it didn’t work. And it’s only after new intuition from the success of machine learning that in 2024 I tried again—and this time it worked. Given an objective like “make a finite pattern that lives as long as possible”, adaptive evolution by successive mutation of rules (say in a cellular automaton) seemed to almost magically find—typically very elaborate—solutions. Soon I had understood that what I was seeing was essentially “raw computational irreducibility” that just “happened” to fit the fairly coarse fitness criteria I was using. And I then argued that the success of biological evolution was the result of the interplay between computationally bounded fitness and underlying computational irreducibility.
But, OK, what did that mean for the “innards” of biological systems? Exploring an idealized version of medicine on the basis of my minimal models of biological evolution led me to look in a bit more detail at the spectrum of behavior in adaptively evolved systems, and in variants produced by perturbations.
But was there something general—something potentially universal—that one could say? In the Second Law one often talks about how behavior one sees is somehow overwhelmingly likely to be “typical of the ensemble of all possibilities”. In the usual Second Law, the possibilities are just different initial configurations of molecules, etc. But in thinking about a system that can change its rules, the ensemble of all possibilities is—at least at the outset—much bigger: in effect it’s the whole ruliad. But the crucial point I realized a few months ago is that the changes in rules that are relevant for biology must be ones that can somehow be achieved by a process of adaptive evolution. But what should the objective of that adaptive evolution be?
One of the key lessons from our Physics Project and the many things informed by it is that, yes, the character of the observer matters—but knowing just a little about an observer can be sufficient to deduce a lot about the laws of behavior that observer will perceive. So that led to the idea that this kind of thing might be true about objective functions—and that just knowing that, for example, an objective function is computationally simple might be enough to tell one things about the “rulial ensemble” of possible rules.
But is that really true? Well, as I have done so many times, I turned to computer experiments to find out. In my work on the foundations of biological evolution I had used what are in a sense very “generic” fitness functions (like overall lifetime). But now I needed a whole spectrum of possible fitness functions—some of them by many measures in fact even simpler to set up than something like lifetime.
The results I’ve reported here I consider very encouraging. The underlying details don’t seem to matter much. But a broad range of computationally simple fitness functions seem to “worm their way down” to have the same kind of effect on small-scale behavior—and to make it in some sense mechanoidal.
Biology has tended to be a field in which one doesn’t expect much in the way of formal theoretical underpinning. And indeed—even after all the data that’s been collected—there are remarkably few “big theories” in biology: natural selection and the digital/informational nature of DNA have been pretty much the only examples. But now, from the type of thinking introduced by our Physics Project, we have something new and different: the concept of the rulial ensemble, and the idea that essentially just from the fact of biological evolution we can talk about certain features of how adaptively evolved systems in biology must work.
Traditional mathematical methods have never gotten very far with the broad foundations of biology. And nor, in the end, has specific computational modeling. But by going to a higher level—and in a sense thinking about the space of all possible computations—I believe we can begin to see a path to a powerful general framework not only for the foundations of biology, but for any system that shows bulk orchestration produced by a process of adaptive evolution.
Thanks
Thanks to Willem Nielsen of the Wolfram Institute for extensive help, as well as to Wolfram Institute affiliates Júlia Campolim and Jesse Angeles Lopez for their additional help. The ideas here have ultimately come together rather quickly, but in both the recent and the distant past discussions with a number of people have provided useful ideas and background—including with Richard Assar, Charles Bennett, Greg Chaitin, Paul Davies, Walter Fontana, Nigel Goldenfeld, Greg Huber, Stuart Kauffman, Chris Langton, Pedro Márquez-Zacarías and Elizabeth Wolfram.


