
Turning LLM Capabilities into Functions
So far, we mostly think of LLMs as things we interact directly with, say through chat interfaces. But what if we could take LLM functionality and “package it up” so that we can routinely use it as a component inside anything we’re doing? Well, that’s what our new LLMFunction is about.
The functionality described here will be built into the upcoming version of Wolfram Language (Version 13.3). To install it in the now-current version (Version 13.2), use
You will also need an API key for the OpenAI LLM or another LLM.
Here’s a very simple example—an LLMFunction that rewrites a sentence in active voice:
Here’s another example—an LLMFunction with three arguments, that finds word analogies:
And here’s one more example—that now uses some “everyday knowledge” and “creativity”:
In each case here what we’re doing is to use natural language to specify a function, that’s then implemented by an LLM. And even though there’s a lot going on inside the LLM when it evaluates the function, we can treat the LLMFunction itself in a very “lightweight” way, using it just like any other function in the Wolfram Language.
Ultimately what makes this possible is the symbolic nature of the Wolfram Language—and the ability to represent any function (or, for that matter, anything else) as a symbolic object. To the Wolfram Language 2 + 3 is Plus[2,3], where Plus is just a symbolic object. And for example doing a very simple piece of machine learning, we again get a symbolic object

which can be used as a function and applied to an argument to get a result:

And so it is with LLMFunction. On its own, LLMFunction is just a symbolic object (we’ll explain later why it’s displayed like this):

But when we apply it to an argument, the LLM does its work, and we get a result:

If we want to, we can assign a name to the LLMFunction

and now we can use this name to refer to the function:
It’s all rather elegant and powerful—and connects quite seamlessly into the whole structure of the Wolfram Language. So, for example, just as we can map a symbolic object f over a list
so now we can map LLMFunction over a list:
And just as we can progressively nest f
so now we can progressively nest an LLMFunction—here producing a “funnier and funnier” version of a sentence:

We can similarly use Outer
to produce an array of LLMFunction results:

It’s remarkable what becomes possible when one integrates LLMs with the Wolfram Language. One thing one can do is take results of Wolfram Language computations (here a very simple one) and feed them into an LLM:
We can also just directly feed in data:

But now we can take this textual output and apply another LLMFunction to it (% stands for the last output):
And then perhaps yet another LLMFunction:
If we want, we can compose these functions together (f@x is equivalent to f[x]):

As another example, let’s generate some random words:
Now we can use these as “input data” for an LLMFunction:
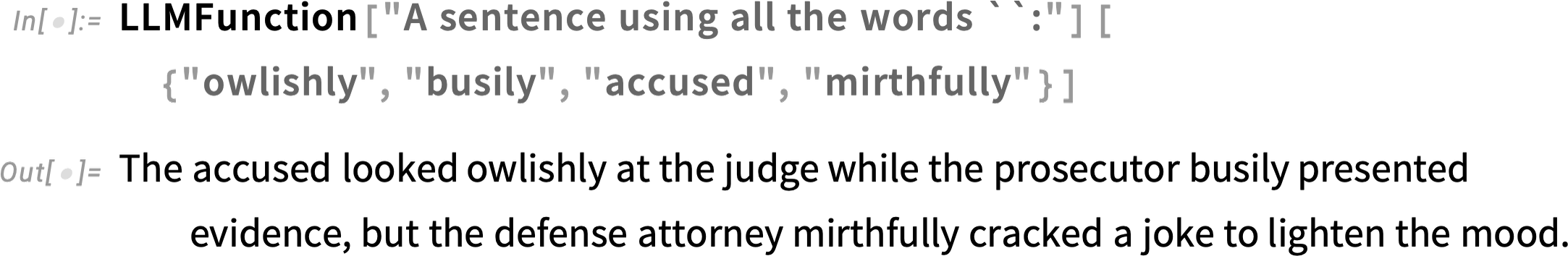
The input for an LLMFunction doesn’t have to be “immediately textual”:
By default, though, the output from LLMFunction is purely textual:
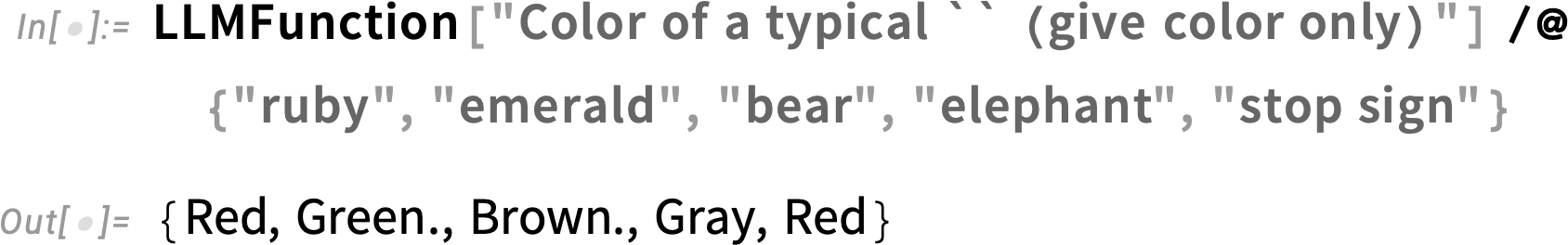
But it doesn’t have to be that way. By giving a second argument to LLMFunction you can say you want actual, structured computable output. And then through a mixture of “LLM magic” and natural language understanding capabilities built into the Wolfram Language, the LLMFunction will attempt to interpret output so it’s given in a specified, computable form.
For example, this gives output as actual Wolfram Language colors:

And here we’re asking for output as a Wolfram Language "City" entity:

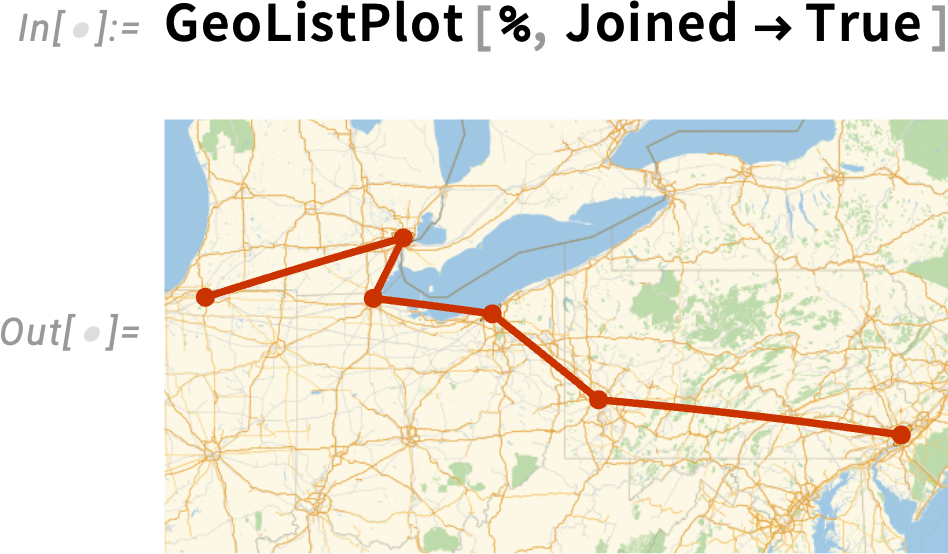
Here’s a slightly more elaborate example where we ask for a list of cities:

And, of course, this is a computable result, that we can for example immediately plot:
Here’s another example, again tapping the “common-sense knowledge” of the LLM:

Now we can immediately use this LLMFunction to sort objects in decreasing order of size:
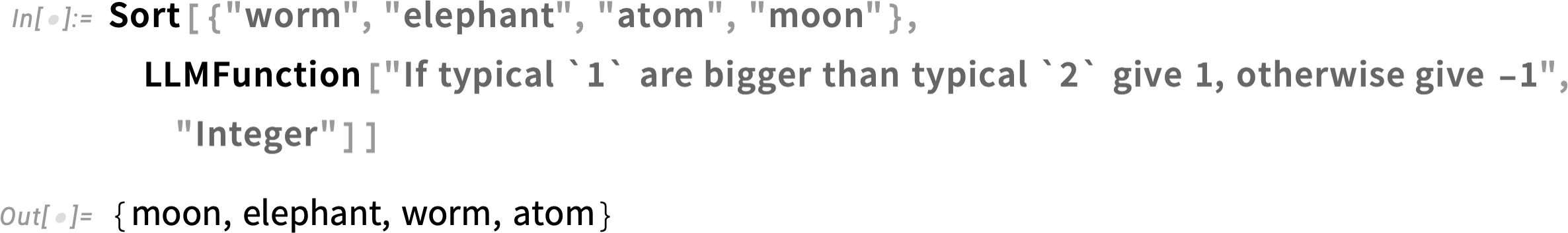
An important use of LLM functions is in extracting structured data from text. Imagine we have the text:

Now we can start asking questions—and getting back computable answers. Let’s define:
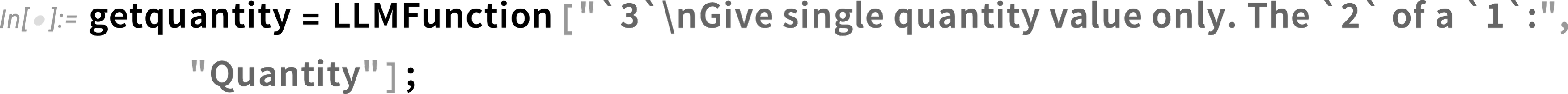
Now we can “ask a quantity question” based on that text:
And we can go on, getting back structured data, and computing with it:
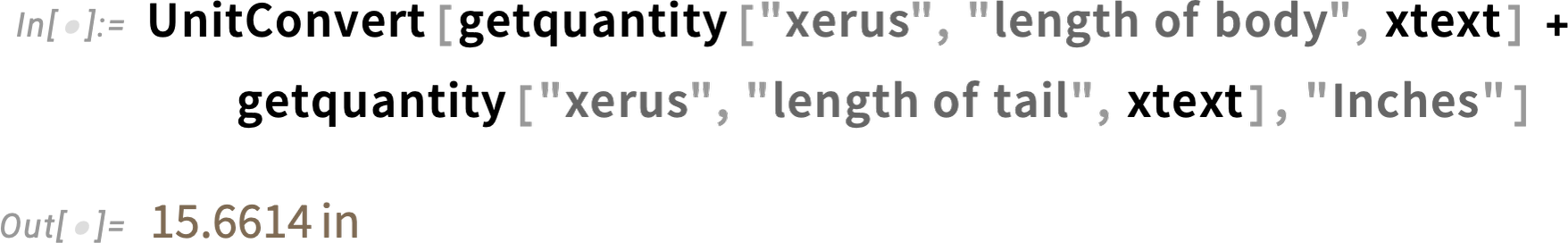
There’s often a lot of “common sense” involved. Like here the LLM has to “figure out” that by “mass” we mean “body weight”:
Here’s another sample piece of text:

And once again we can use LLMFunction to ask questions about it, and get back structured results:


There’s a lot one can do with LLMFunction. Here’s an example of an LLMFunction for writing Wolfram Language:
The result is a string. But if we’re brave, we can turn it into an expression, which will immediately be evaluated:
Here’s a “heuristic conversion function”, where we’ve bravely specified that we want the result as an expression:

Functions from Examples
LLMs—like typical neural nets—are built by learning from examples. Initially those examples include billions of webpages, etc. But LLMs also have an uncanny ability to “keep on learning”, even from very few examples. And LLMExampleFunction makes it easy to give examples, and then have the LLM apply what it’s learned from them.
Here we’re giving just one example of a simple structural rearrangement, and—rather remarkably—the LLM successfully generalizes this and is immediately able to do the “correct” rearrangement in a more complicated case:
Here we’re again giving just one example—and the LLM successfully figures out to sort in numerical order, with letters before numbers:
LLMExampleFunction is pretty good at picking up on “typical things one wants to do”:
But sometimes it’s not quite sure what’s wanted:
Here’s another case where the LLM gives a good result, effectively also pulling in some general knowledge (of the meaning of ♂ and ♀):
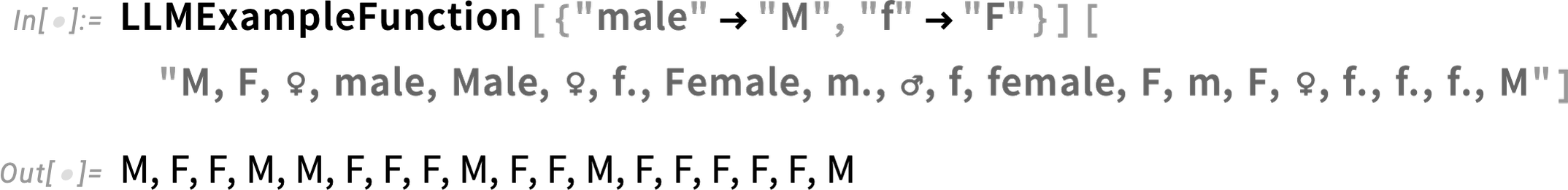
One powerful way to use LLMExampleFunction is in converting between formats. Let’s say we produce the following output:

But instead of this “ASCII art”-like rendering, we want something that can immediately be given as input to Wolfram Language. What LLMExampleFunction lets us do is give one or more examples of what transformation we want to do. We don’t have to write a program that does string manipulation, etc. We just have to give an example of what we want, and then in effect have the LLM “generalize” to all the cases we need.
Let’s try a single example, based on how we’d like to transform the first “content line” of the output:
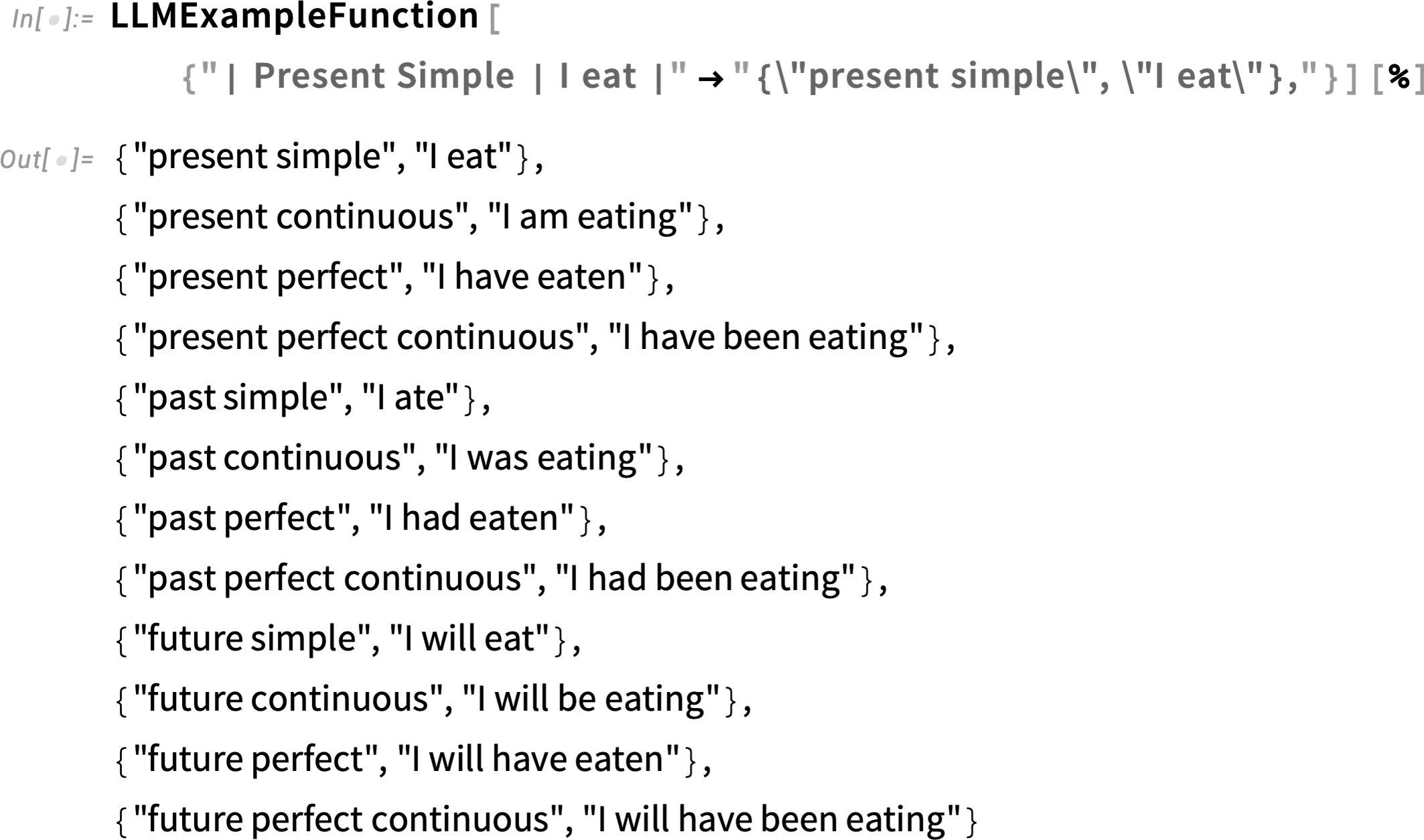
And, yes, this basically did what we need, and it’s straightforward to get it into a final Wolfram Language form:

So far we’ve just seen LLMExampleFunction doing essentially “structure-based” operations. But it can also do more “meaning-based” ones:
Often one ends up with something that can be thought of as an “analogy question”:
When it comes to more computational situations, it can do OK if one’s asking about things which are part of the corpus of “common-sense computational knowledge”:
But if there’s “actual computation” involved, it typically fails (the right answer here is
Sometimes it’s hard for LLMExampleFunction to figure out what you want just from examples you give. Here we have in mind finding animals of the same color—but LLMExampleFunction doesn’t figure that out:
But if we add a “hint”, it’ll nail it:
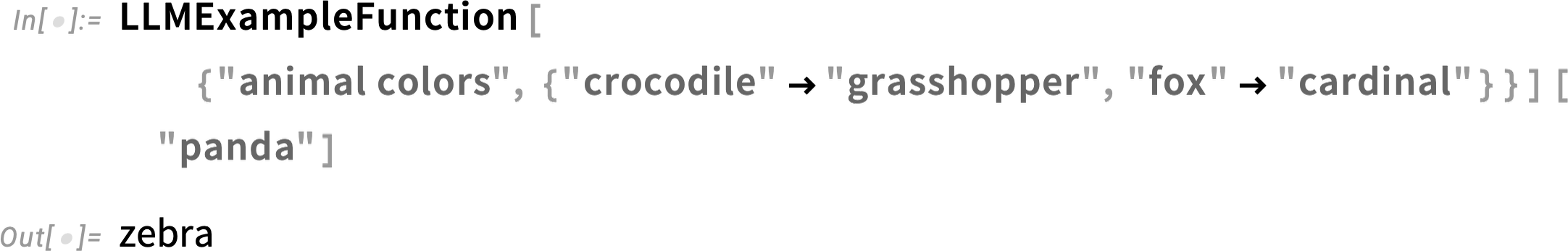
We can think of LLMExampleFunction as a kind of textual analog of Predict. And, like Predict, LLMExampleFunction can take also examples in an all-inputs → all-outputs form:
Pre-written Prompts and the Wolfram Prompt Repository
So far we’ve been talking about creating LLM functions “from scratch”, in effect by explicitly writing out a “prompt” (or, alternatively, giving examples to learn from). But it’s often convenient to use—or at least include—“pre-written” prompts, either ones that you’ve created and stored before, or ones that come from our new Wolfram Prompt Repository:

Other posts in this series will talk in more detail about the Wolfram Prompt Repository—and about how it can be used in things like Chat Notebooks. But here we’re going to talk about how it can be used “programmatically” for LLM functions.
The first approach is to use what we call “function prompts”—that are essentially pre-built LLMFunction objects. There’s a whole section of function prompts in the Prompt Repository. As one example, let’s consider the "Emojify" function prompt. Here’s its page in the Prompt Repository:

You can take any function prompt and apply it to specific text using LLMResourceFunction. Here’s what happens with the "Emojify" prompt:
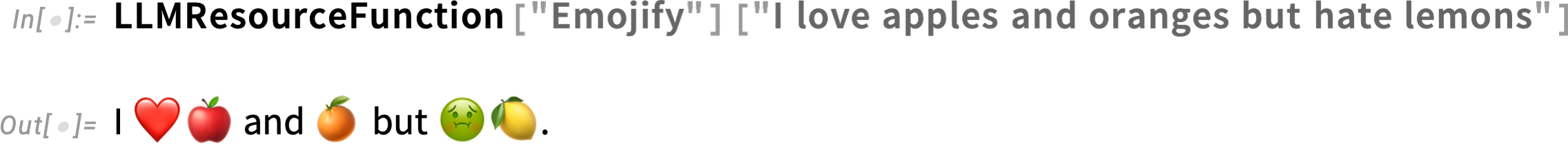
And if you look at the pure result from LLMResourceFunction, we can see that it’s just an LLMFunction—whose content was obtained from the Prompt Repository:

Here’s another example:
And here we’re applying two different (but, in this particular case, approximately inverse) LLM functions from the Prompt Repository:
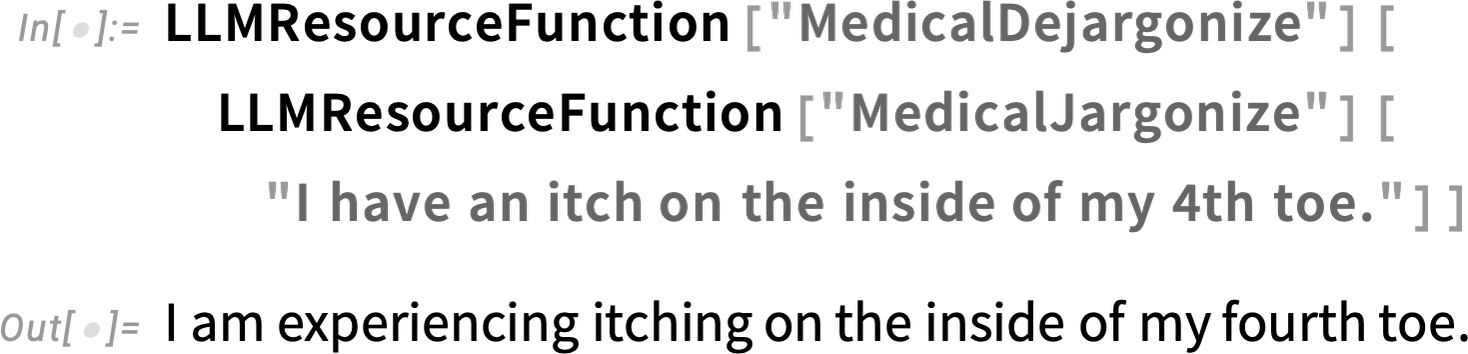
LLMResourceFunction can take more than one argument:

Something that we see here is that LLMResourceFunction can have an interpreter built into it—so that instead of just returning a string, it can return a computable (here held) Wolfram Language expression. So, for example, the "MovieSuggest" prompt in the Prompt Repository is defined to include an interpreter that gives "Movie" entities

from which we can do further computations, like:

Besides “function prompts”, another large section of the Prompt Repository is devoted to “persona” prompts. These are primarily intended for chats (“talk to a particular persona”), but they can also be used “programmatically” through LLMResourceFunction to ask for a single response “from the persona” to a particular input:

Beyond function and persona prompts, there’s a third major kind of prompt—that we call a “modifier prompt”—that’s intended to modify output from the LLM. An example of a modifier prompt is "ELI5" (“Explain Like I’m 5”). To “pull in” such a modifier prompt from the Prompt Repository, we use the general function LLMPrompt.
Say we’ve got an LLMFunction set up:
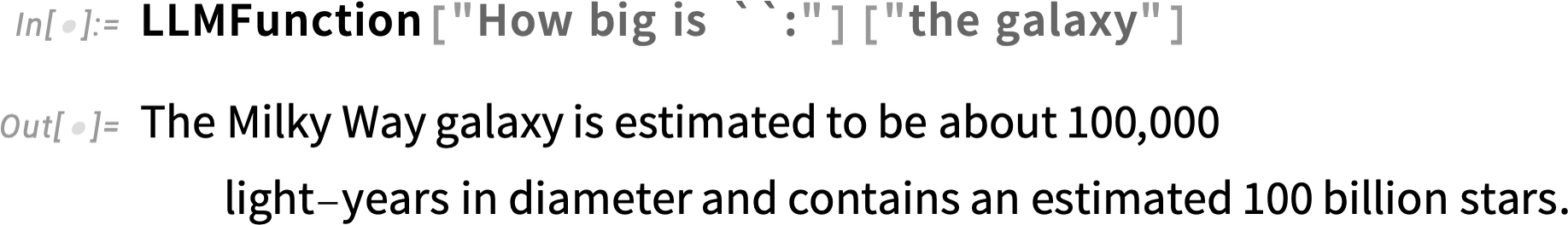
To modify it with "ELI5", we just insert LLMPrompt["ELI5"] into the “body” of the LLMFunction:
You can include multiple modifier prompts; some modifier prompts (like "Translated") are set up to “take parameters” (here, the language to have the output translated into):

We’ll talk later in more detail about how this works. But the basic idea is just that LLMPrompt retrieves representations of prompts from the Prompt Repository:

An important kind of modifier prompts are ones intended to force the output from an LLMFunction to have a particular structure, that for example can readily be interpreted in computable Wolfram Language form. Here we’re using the "YesNo" prompt, that forces a yes-or-no answer:
By the way, you can also use the "YesNo" prompt as a function prompt:
And in general, as we’ll discuss later, there’s actually lots of crossover between what we’ve called “function”, “persona” and “modifier” prompts.
The Wolfram Prompt Repository is intended to have lots of good, useful prompts in it, and to provide a curated, public collection of prompts. But sometimes you’ll want your own, custom prompts—that you might want to share, either publicly or with a specific group. And—just as with the Wolfram Function Repository, Wolfram Data Repository, etc.—you can use exactly the same underlying machinery as the Wolfram Prompt Repository to do this.
Start by bringing up a new Prompt Resource Definition notebook (use the New > Repository Item > Prompt Repository Item menu item). Then fill this out with whatever definition you want to give:

There’s a button to submit your definition to the public Prompt Repository. But instead of using this, you can go to the Deploy menu, which lets you deploy your definition either locally, or publicly or privately to the cloud (or just within the current Wolfram Language session).
Let’s say you deploy publicly to the cloud. Then you’ll get a “documentation” webpage:

And to use your prompt, anyone just has to give its URL:

LLMPrompt gives you a representation of the prompt you wrote:

How It All Works
We’ve seen how LLMFunction, LLMPrompt, etc. can be used. But now let’s talk about how they work at an underlying Wolfram Language level. Like everything else in Wolfram Language, LLMFunction, LLMPrompt, etc. are symbolic objects. Here’s a simple LLMFunction:

And when we apply the LLMFunction, we’re taking this symbolic object and supplying some argument to it—and then it’s evaluating to give a result:

But what’s actually going on underneath? There are two basic steps. First a piece of text is created. And then this text is fed to the LLM—which generates the result which is returned. So how is the text created? Essentially it’s through the application of a standard Wolfram Language string template:
And then comes the “big step”—processing this text through the LLM. And this is achieved by LLMSynthesize:
LLMSynthesize is the function that ultimately underlies all our LLM functionality. Its goal is to do what LLMs fundamentally do—which is to take a piece of text and “continue it in a reasonable way”. Here’s a very simple example:
When you do something like ask a question, LLMSynthesize will “continue” by answering it, potentially with another sentence:
There are lots of details, that we’ll talk about later. But we’ve now seen the basic setup, at least for generating textual output. But another important piece is being able to “interpret” the textual output as a computable Wolfram Language expression that can immediately plug into all the other capabilities of the Wolfram Language. The way this interpretation is specified is again very straightforward: you just give a second argument to the LLMFunction.
If that second argument is, say, f, the result you’ll get just has f applied to the textual output:
But what’s actually going on is that Interpreter[f]1 is being applied, which for the symbol f happens to be the same as just applying f. But in general Interpreter is what provides access to the powerful natural language understanding capabilities of the Wolfram Language—that allow you to convert from pure text to computable Wolfram Language expressions. Here are a few examples of Interpreter in action:


So now, by including a "Color" interpreter, we can make LLMFunction return an actual symbolic color specification:
Here’s an example where we’re telling the LLM to write JSON, then interpreting it:

A lot of the operation of LLMFunction “comes for free” from the way string templates work in the Wolfram Language. For example, the “slots” in a string template can be sequential
or can be explicitly numbered:
And this works in LLMFunction too:
You can name the slots in a string template (or LLMFunction), and fill in their values from an association:

If you leave out a “slot value”, StringTemplate will by default just leave a blank:
String templates are pretty flexible things, not least because they’re really just special cases of general symbolic template objects:

What is an LLMExampleFunction? It’s actually just a special case of LLMFunction, in which the “template” is constructed from the “input-output” pairs you specify:

An important feature of LLMFunction is that it lets you give lists of prompts, that are combined:
And now we’re ready to talk about LLMPrompt. The ultimate goal of LLMPrompt is to retrieve pre-written prompts and then derive from them text that can be “spliced into” LLMSynthesize. Sometimes prompts (say in the Wolfram Prompt Repository) could just be pure pieces of text. But sometimes they need parameters. And for consistency, all prompts from the Prompt Repository are given in the form of template objects.
If there are no parameters, here’s how you can extract the pure text form of an LLMPrompt:
LLMSynthesize effectively automatically resolves any LLMPrompt templates given in it, so for example this immediately works:

And it’s this same mechanism that lets one include LLMPrompt objects inside LLMFunction, etc.
By the way, there’s always a “core template” in any LLMFunction. And one way to extract that is just to apply LLMPrompt to LLMFunction:

It’s also possible to get this using Information:

When you include (possibly several) modifier prompts in LLMSynthesize, LLMFunction, etc. what you’re effectively doing is “composing” prompts. When the prompts don’t have parameters this is straightforward, and you can just give all the prompts you want directly in a list.
But when prompts have parameters, things are a bit more complicated. Here’s an example that uses two prompts, one of which has a parameter:

And the point is that by using TemplateSlot we can “pull in” arguments from the “outer” LLMFunction, and use them to explicitly fill arguments we need for an LLMPrompt inside. And of course it’s very convenient that we can use general Wolfram Language TemplateObject technology to specify all this “plumbing”.
But there’s actually even more that TemplateObject technology gives us. One issue is that in order to feed something to an LLM (or, at least, a present-day one), it has to be an ordinary text string. Yet it’s often convenient to give general Wolfram Language expression arguments to LLM functions. Inside StringTemplate (and LLMFunction) there’s an InsertionFunction option, that specifies how things are supposed to be converted for insertion—and the default for that is to use the function TextString, which tries to make “reasonable textual versions” of any Wolfram Language expression.
So this is why something like this can work:
It’s because applying the StringTemplate turns the ![]() expression into a string (in this case RGBColor[…]) that the LLM can process.
expression into a string (in this case RGBColor[…]) that the LLM can process.
It’s always possible to specify your own InsertionFunction. For example, here’s an InsertionFunction that “reads an image” by using ImageIdentify to find what’s in it:

What about the LLM Inside?
LLMFunction etc. “package up” LLM functionality so that it can be used as an integrated part of the Wolfram Language. But what about the LLM inside? What specifies how it’s set up?
The key is to think of it as being what we’re calling an “LLM evaluator”. In using Wolfram Language the default is to evaluate expressions (like 2 + 2) using the standard Wolfram Language evaluator. Of course, there are functions like CloudEvaluate and RemoteEvaluate—as well as ExternalEvaluate—that do evaluation”elsewhere”. And it’s basically the same story for LLM functions. Except that now the “evaluator” is an LLM, and “evaluation” means running the LLM, ultimately in effect using LLMSynthesize.
And the point is that you can specify what LLM—with what configuration—should be used by setting the LLMEvaluator option for LLMSynthesize, LLMFunction, etc. You can also give a default by setting the global value of $LLMEvaluator.
Two basic choices of underlying model right now are "GPT-3.5-Turbo", "GPT-4" (as well as other OpenAI models)—and there’ll be more in the future. You can specify which of these you want to use in the setting for LLMEvaluator:


When you “use a model” you’re (at least for now) calling an API—that needs authentication, etc. And that is handled either through Preferences settings, or programmatically through ServiceConnect—with help from SystemCredential, Environment, etc.
Once you’ve specified the underlying model, another thing you’ll often want to specify is a list of initial prompts (which, technically, are inserted as "System"-role prompts):

In another post we’ll discuss the very powerful concept of adding tools to an LLM evaluator—which allow it to call on Wolfram Language functionality during its operation. There are various options to support this. One is "StopTokens"—a list of tokens which, if encountered, should cause the LLM to stop generating output, here at the “ff” in the word “giraffe”:

LLMConfiguration lets you specify a full “symbolic LLM configuration” that precisely defines what LLM, with what configuration, you want to use:

There’s one particularly important further aspect of LLM configurations to discuss, and that’s the question of how much randomness the LLM should use. The most common way to specify this is through the "Temperature" parameter. Recall that at each step in its operation an LLM generates a list of probabilities for what the next token in its output should be. The "Temperature" parameter determines how to actually generate a token based on those probabilities.
Temperature 0 always “deterministically” picks the token that is deemed most probable. Nonzero temperatures explicitly introduce randomness. Temperature 1 picks tokens according to the actual probabilities generated by the LLM. Lower temperatures favor words that were assigned higher probabilities; higher temperature “reach further” to words with lower probabilities.
Lower temperatures generally lead to “flatter” but more reliable and reproducible results; higher temperatures introduce more “liveliness”, but also more of a tendency to “go off track”.
Here’s what happens at zero temperature (yes, a very “flat” joke):
Now here’s temperature 1:
There’s always randomness at temperature 1, so the result will typically be different every time:

If you increase the temperature too much, the LLM will start “melting down”, and producing nonsense:

At temperature 2 (the current maximum) the LLM has effectively gone completely bonkers, dredging up all sorts of weird stuff from its “subconscious”:

In this case, it goes on for a long time, but finally hits a stop token and stops. But often at higher temperatures you’ll have to explicitly specify the MaxItems option for LLMSynthesize, so you cut off the LLM after a given number of tokens—and don’t let it “randomly wander” forever.
Now here comes a subtlety. While by default LLMFunction uses temperature 0, LLMSynthesize instead uses temperature 1. And this nonzero temperature means that LLMSynthesize will by default typically generate different results every time it’s used:
So what about LLMFunction? It’s set up to be by default as “deterministic” and repeatable as possible. But for subtle and detailed reasons it can’t be perfectly deterministic and repeatable, at least with typical current implementations of LLM neural nets.
The basic issue is that current neural nets operate with approximate real numbers, and occasionally roundoff in those numbers can be critical to “decisions” made by the neural net (typically because the application of the activation function for the neural net can lead to a bifurcation between results from numerically nearby values). And so, for example, if different LLMFunction evaluations happen on servers with different hardware and different roundoff characteristics, the results can be different.
But actually the results can be different even if exactly the same hardware is used. Here’s the typical (subtle) reason why. In a neural net evaluation there are lots of arithmetic operations that can in principle be done in parallel. And if one’s using a GPU there’ll be units that can in principle do certain numbers of these operations in parallel. But there’s typically elaborate real-time optimization of what operation should be done when—that depends, for example, on the detailed state and history of the GPU. But so what? Well, it means that in different cases operations can end up being done in different orders. So, for example, one time one might end up computing (a + b) + c, while another time one might compute a + (b + c).
Now, of course, in standard mathematics, for ordinary numbers a, b and c, these forms are always identically equal. But with limited-precision floating-point numbers on a computer, they sometimes aren’t, as in a case like this:
And the presence of even this tiny deviation from associativity (normally only in the least significant bit) means that the order of operations in a GPU can in principle matter. At the level of individual operations, it’s a small effect. But if one “hits a bifurcation” in the neural net, there can end up being a cascade of consequences, leading eventually to a different token being produced, and a whole different “path of text” being generated—all even though one is “operating at zero temperature”.
Most of the time this is quite a nuisance—because it means you can’t count on an LLMFunction doing the same thing every time it’s run. But sometimes you’ll specifically want an LLMFunction to be a bit random and “creative”—which is something you can force by explicitly telling it to use a nonzero temperature. So, for example, with default zero temperature, this will usually give the same result each time:
But with temperature 1, you’ll get different results each time (though the LLM really seems to like Sally!):


AI Wrangling and the Art of Prompts
There’s a certain systematic and predictable character to writing typical Wolfram Language. You use functions that have been carefully designed (with great effort, over decades, I might add) to do particular, well-specified and documented things. But setting up prompts for LLMs is a much less systematic and predictable activity. It’s more of an art—where one’s effectively probing the “alien mind” of the LLM, and trying to “wrangle” it to do what one wants.
I’ve come to believe, though, that the #1 thing about good prompts is that they have to be based on good expository writing. The same things that make a piece of writing understandable to a human will make it “understandable” to the LLM. And in a sense that’s not surprising, given that the LLM is trained in a very “human way”—from human-written text.
Consider the following prompt:
In this case it does what one probably wants. But it’s a bit sloppy. What does “reverse” mean? Here it interprets it quite differently (as character string reversal):
Better wording might be:
But one feature of an LLM is that whatever input you give, it’ll always give some output. It’s not really clear what the “opposite” of a fish is—but the LLM offers an opinion:
But whereas in the cases above the LLMFunction just gave single-word outputs, here it’s now giving a whole explanatory sentence. And one of the typical challenges of LLMFunction prompts is trying to be sure that they give results that stay in the same format. Quite often telling the LLM what format one wants will work (yes, it’s a slightly dubious “opposite”, but not completely crazy):
Here we’re trying to constrain the output more—which in this case worked, though the actual result was different:

It’s often useful to give the LLM examples of what you want the output to be like (the \n newline helps separate parts of the prompt):
But even when you think you know what’s going to happen, the LLM can sometimes surprise you. This finds phonetic renditions of words in different forms of English:
So far, consistent formats. But now look at this (!):
If you give an interpretation function inside LLMFunction, this can often in effect “clean up” the raw text generated by the LLM. But again things can go wrong. Here’s an example where many of the colors were successfully interpreted, but one didn’t make it:

(The offending “color” is “neon”, which is really more like a class of colors.)
By the way, the general form of the result we just got is somewhat remarkable, and characteristic of an interesting capability of LLMs—effectively their ability to do “linguistic statistics” of the web, etc. Most likely the LLM never specifically saw in its training data a table of “most fashionable colors”. But it saw lots of text about colors and fashions, that mentioned particular years. If it had collected numerical data, it could have used standard mathematical and statistical methods to combine it, look for “favorites”, etc. But instead it’s dealing with linguistic data, and the point is that the way an LLM works, it’s in effect able to systematically handle and combine that data, and derive “aggregated conclusions” from it.
Symbolic Chats
In LLMFunction, etc. the underlying LLM is basically always called just once. But in a chatbot like ChatGPT things are different: there the goal is to build up a chat, with the LLM being called repeatedly, as things go back and forth with a (typically human) “chat partner”. And along with the release of LLMFunction, etc. we’re also releasing a symbolic framework for “LLM chats”.
A chat is always represented by a chat object. This creates an “empty chat”:

Now we can take the empty chat, and “make our first statement”, to which the LLM will respond:

We can add another back and forth:

At each stage the ChatObject represents the complete state of the chat so far. So it’s easy for us to go back to a given state, and “go on differently” from there:

What’s inside a ChatObject? Here’s the basic structure:

The “roles” are defined by the underlying LLM; in this case they’re “User” (i.e. content provided by the user) and “Assistant” (i.e. content generated automatically by the LLM).
When an LLM generates new output in chat, it’s always reading everything that came before in the chat. ChatObject has a convenient way to find out how big a chat has got:

ChatObject typically displays as a chat history. But you can create a ChatObject by giving the explicit messages you want to appear in the initial chat—here based on one part of the history above—and then run ChatEvaluate starting from that:

What if you want to have the LLM “adopt a particular persona”? Well, you can do that by giving an initial ("System") prompt, say from the Wolfram Prompt Repository, as part of an LLMEvaluator specification:

Having chats in symbolic form makes it possible to build and manipulate them programmatically. Here’s a small program that effectively has the AI “interrogate itself”, automatically switching back and forth being the “User” and “Assistant” sides of the conversation:


This Is Just the Beginning…
There’s a lot that can be done with all the new functionality we’ve discussed here. But actually it’s just part of what we’ve been able to develop by combining our longtime tower of technology with newly available LLM capabilities. I’ll be describing more in subsequent posts.
But what we’ve seen here is essentially the “call an LLM from within Wolfram Language” side of things. In the future, we’ll discuss how Wolfram Language tools can be called from within an LLM—opening up very powerful multi-pass automatic “collaboration” between LLMs and Wolfram Language. We’ll also in the future discuss how a new kind of Wolfram Notebooks can be used to provide a uniquely effective interactive interface to LLMs. And there’ll be much more too. Indeed, almost every day we’re uncovering remarkable new possibilities.
But LLMFunction and the other things we’ve discussed here form an important foundation for what we can now do. Extending what we’ve done over the past decade or more in machine learning, they form a key bridge between the symbolic world that’s at the core of the Wolfram Language, and the “statistical AI” world of LLMs. It’s a uniquely powerful combination that we can expect to represent an anchor piece of what can now be done.

